773 total views
Visst har vi Teams og andre skybaserte systemer for å samarbeide gjennom nettet, men vi har også behov for noe enklere for små grupper med veldefinerte samarbeidsmodeller. Vi skal vise et slikt system her, og påpeke hvilke fordeler som følger av et kompakt og fokusert system.
CMS-demonstratoren kan kjøres fra adressen http://hos.fongen.no/cms
Kildekoden i arkivform kan lastes ned fra denne lenken
(c) Anders Fongen, 2024
Innledning
Se for deg en gruppe med noen titalls medlemmer, som skal samarbeide om en fokusert og veldefinert oppgave. F.eks planlegging og utforming av et undervisningsfag, en leteoperasjon etter savnede personer, en oppgave knyttet til kartlegging og etterretning, skriving av sakprosa, en chat.
Slike oppgaver er kjennetegnet ved visse egenskaper og behov:
- Enkle behov for typografisk formatering av tekst
- Behov for enkelt å opprette nye dokumenter, og endre på eksisterende
- Høy tillit mellom deltakerne, med felles fokus og nødvendig kompetanse
- Behov for raskt å gjøre seg kjent med andres bidrag til en aktivitet
- Enkelt å fjerne utdatert, irrelevant og distraherende innhold
For slike oppgaver er det kanskje fristende å ta frem et generisk samarbeidverktøy med stort behov for styring og konfigurasjon, med høye kapasitetskrav til utstyr og kommunikasjonskanaler. F.eks. Teams, DocuLive, Itslearning, Canvas, Google Disk. Disse dekker muligens behovet, men ikke nødvendigvis på den mest effektive måte, de kan nelig fremstå som en “skyte spurv med kanoner”-løsning. Dessuten trenger de en internett-forbindelse til en skytjeneste, bare så det er sagt.
Vi skal i denne artikkelen presentere et enkelt samarbeidssystem kalt CMS – Content Management System. CMS kjennetegnes ved følgende egenskaper:
- Minimalt med programkode, < 300 linjer i Python
- Bruker markdown syntaks for tekstformatering
- Web brukergrensesnitt (krever kun en web-leser)
- Dokumentlås som virker
- Enkel mekanisme for adgangskontroll
- Dokumenter kan “oppfriskes” automatisk av web-leseren
- Dokumenter kan opprettes og redigeres gjennom MQTT-protokoll
- OpenSource, enkel kode for enkel utvidelse og endring
La oss i resten av dette dokumentet presentere disse egenskapene enkeltvis, og forklare hvordan de støtter aktuelle brukstilfeller. En grundigere presentasjon ligger i selve CMS-systemets demonstrasjonstjener på http://hos.fongen.no/cms.
Agil utviklingsmetodikk og Wiki
Behovene som ble listet opp i innledningen minner mye om egenskaper ved moderne system- og programutvikling, kjent som “agile development”. Gå gjerne via denne lenken for å lese litt om “agile” metoder (“agil” har i mellomtiden rukket å bli et norsk ord med norsk uttale).
For å støtte agilt samarbeid utviklet Ward Cunningham i 1995 en dokumentlagringstjeneste kalt Wiki. Med en Wiki kan enhver bruker opprette, redigere og slette dokumenter, altså et fravær av adgangskontroll som kun fungerer i grupper med felles mål og metode. En Wiki kan skrives kompakt med kun noen titalls programlinjer, men uten en redaktør som kan jobbe som “husmor” er de fleste erfaringer den at dokumentsamlingen med tiden blir en uhåndterlig blanding av nyttige, feilaktige, overlappende og utdaterte dokumenter. Wiki-prinsippet finnes også i Wikipedia, men her er det ansatt husmødre som overvåker redigeringen og opprettelsen av nye sider.
Den positive erfaringen med Wiki-prinsippet at en “90%”-løsning, dvs. 90% av behovene til en samarbeidsgruppe, lar seg løse med enkel og kompakt programmering, mens en 99%-løsning er kanskje 100 ganger større og dyrere. Såkalt “feature creep” i systemspesifikasjonene, dvs. at stadig nye funksjonskrav blir lagt til underveis, er en svært dyr uvane, og en fokusert og nøktern “90%”-løsning kan gi mye bedre effekt av innsatsen.
Overordnet beskrivelse av CMS
Dette er en web-tjeneste programmert i Python over rammeverket web.py, og som lar en gruppe av brukere søke, opprette og redigere dokumenter direkte fra sin web-leser. Den skiller mellom “lese”- og “redigere”-brukere slik at kun sistnevnte kan endre innholdet av dokumentsamlingen.
Brukerkontroll
Skillet mellom de to brukergruppene (“lese” og “redigere”) kan gjøres på mange måter, men for å unngå egne tabeller over brukernavn og passord (vi har nok av passord å huske på allerede) har jeg testet ut to metoder: IP-adresser eller klient-sertifikater:
IP-adresser: Bare klienter med IP-adresser som brukes bak brannveggen gir redigeringstillatelse, f.eks. IP-adresser som begynner med 192.168.x.x. Klienter forespørsler fra Internet vil aldri bruke disse adressene. Klienter tilkoplet via Virtuelle Private Nett (VPN) vil derimot kunne bruke adresser som gir redigeringstillatelse.
Klient-sertifikater: Der hvor det benyttes TLS (https:…) protokoll mellom klienten og tjeneneren kan TLS også sørge for at klientmaskinen må fremvise et nøkkelsertifikat og demonstrere sin private nøkkel for å autentisere seg. Kun de klientene som gjennomfører autentisering får redigeringstillatelse, alle andre kun lesetillatelse. Bruk av klient-sertifikater har den fordel at brukerne blir identifisert individuelt og man kan loggføre den enkelte brukers aktiviteter.
Dokumentorganisering
Dokumentene i CMS er hierarkisk organisert omtrent slik som i et filsystem, men istedetfor filkataloger brukes “mor-dokumenter”. Ethvert dokument kan være “mor” til et antall underordnete dokumenter. De underordnete dokumentene med felles mor kalles “søsken”. Når et dokument vises på skjermen vil både de underordnede dokumentene og søsken-dokumentene vises på et sidepanel. CMS inneholder også en enkel søkefunksjon hvor det kan søkes etter ordforekomster i tittel og innhold.
Dokumentene i CMS ligger lagret i en database, ikke som separate filer. Det åpner for en rekke muligheter for å sortere og søke i dokumenter, etablere reasjoner mellom dokumenter, låse dokumenter under redigering osv. Det åpner også for muligheten for andre programmer å skrive direkte til databasen for f.eks. å opprette dokumenter automatisk. Dette er en viktig egenskap ved CMS som vi skal omtale senere.
Redigering med MarkDown
De fleste er vant til å se en ferdig layout når dokumentet redigeres, på den fom det vil bli presentert for en som leser det. Det finnes andre måter å redigere på hvor layout påføres dokumentet som instruksjoner i tekstformat. Hypertext Markup Language (HTML) er det mest kjente eksemplet, hvor f.eks. teksten “<h2>” ikke vises i web-leseren, men indikerer at påfølgende tekst skal vises som en overskrift. Latex er et velkjent system for fremstilling av vitenskapelige artikler som benytter det samme prinsippet.
En av fordelene med markup er at instruksjonene indikerer intensjonen til forfatteren, ikke nøyaktig hvordan utseendet skal bli. “<h2>” kan resultere i ulik utseende, men alltid i form som indikerer en overskrift. En fargeskriver kan gi overskriften en annen uforming enn en svart-hvitt skriver f.eks.
Markdown er et “slenguttrykk” for et markup-språk som produserer HTML-kodet innhold. Markdown er ofte et enkelt sett av instruksjoner i en kort og enkel form, som f.eks. _underlinjert_ eller **uthevet** skrift. Når dokumentet blir presentert vil disse kodene være erstattet av den ønskede layouten. Wiki-systemene har ofte benyttet en form for markdown ved redigering.
Den viktigste egenskapen ved markdown er derimot at et slikt manuskript føles enkelt og naturlig å lese, også uten omforming av instruksjonene. Her er noen eksempler på tekst skrevet med HTML, Latex og Markdown, for å vise at sistnevnte er lettest å lese. Et dokument som ser slik ut:

Kan skrives med henholdsvis HTML, Latex og Markdown på denne måten:
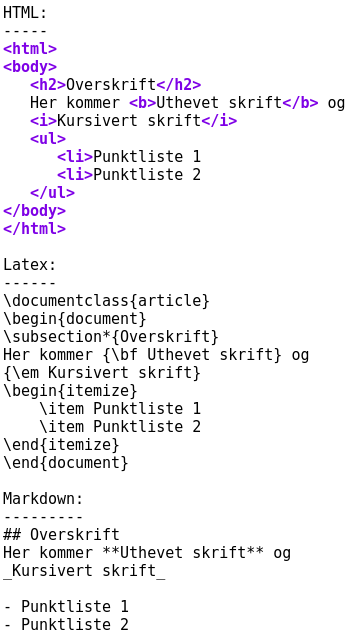
Det er lett å konstatere fra dette eksemplet at Markdown er lettere å skrive inn, og lettere å lese i manuskriptform. I andre enden finner vi Latex, med kraftige mekanismer for å organisere layout og struktur på dokumentet, men som også er tung å skrive inn og vanskelig å lese i manuskriptform.
Markdown kan behandles av programkode for å f.eks. fremstille HTML kode for fremvisning i en web-leser. Med enkle regler kan Markdown behandles med såkalt regulære uttrykk i mange programmeringsspråk, men det finnes også egne programbiblioteker og ferdige programmer som kan gjøre dette. Dette er “kjedelig” programmeringsarbeid og en jobb som er godt å slippe.
Programmet heter pandoc, og finnes i versjoner for Mac, Linux og Windows. Det finnes også et Python-bibliotek kalt pypandoc som tilbyr et utvalg av pandoc’s muligheter gjort tilgjengelig for et Python-program.
Låsing av dokumenter under redigering
Kan flere brukere redigere samme dokument samtidig? I prinsippet ja, og Google Drive tillater nettopp det, men da må de i fellesskap sørge for at dokumentets innhold forblir meningsfylt og sammenhengende. I de fleste tilfellene er det tilstrekkelig løsning å la kun én bruker redigere, og andre som også ønsker dette, må vente på tur. Microsoft Word har lenge hatt en slik “lås”, som åpnes først når dokumentet lukkes etter bruk.
Dette har aldri fungert godt! Alle som har redigert med Word eller Excel har opplevd at en kollega har gått hjem for dagen uten å lukke dokumentet, som da forblir låst inntil neste dag.
I CMS er det valgt en låsemekanisme som automatisk åpner seg etter en viss tid (5 minutter), eller når dokumentet lukkes etter redigering. Dette er et kompromiss: Det løser problemet med gjenglemte låser, men gir brukeren 5 minutter på å fullføre redigeringen (må da gå ut av redigeringen og inn igjen). Dette skjer ved et triks i databasen som også sikrer at flere ikke kan låse et dokument samtidig. Sjekk kildekoden for å se hvilken SQL-syntaks som brukes.
Overvåking av dokumenter
Alle dokumenter i databasen er påført en “refresh rate”, dvs. et tidsrom mellom hver gang dokumentet skal hentes på nytt av web-leseren. Om “refresh rate” er satt til 10 sekunder, vil endringer i dokumentet (gjort av andre) vises frem i alle web-lesere som ser på dette dokumentet senest etter 10 sekunder. Slik kan f.eks. en situasjonsrapport alltid bli vist med de siste oppdateringene uten at brukerne på gjøre en “reload” av dokumentet.
Denne mekanismen introduserer en nødvendig balanse mellom akseptabel forsinkelse i oppdateringen av andre klienter, og den nettverkstrafikken som oppstår knyttet til den stadige hentingen av dokumenttdata. Settes “refresh rate” til 0 skjer ingen slik oppdatering automatisk.
Bruk av bilder
Bilder kan settes inn i dokumentene som redigeres ved å skrive inn en instruksjon i den løpende teksten: <img src=Pictures/filnavn.jpg>. Dette er den vanlige HTML-kommandoen som brukes for dette formålet, og ekstra parametre for å justere størrelse kan også brukes.
Alle bilder legges på samme katalog (Pictures) på CMS-tjenerens filområde, og nye bilder kan lastes opp i PNG eller JPG-format ved å klikke på en knapp i det høyre sidepanelet. Pass på at bildene får unike filnavn, og bilder som ligger der kan inkluderes i mange dokumenter.
Automatiske dokumenter – Internet of things
Automatiske dokumenter betegner dokumenter som legges inn i databasen uten medvirkning fra brukerne av systemet. Disse dokumentene vises frem som andre dokumenter, og egner seg for å vise data fra miljøsensorer, web-kameraer, mashup fra internettkilder (værmelding, trafikkrapporter, børsdata) osv. Et automatisk dokument kombinert med bruk av “refresh rate” kan vise et situasjonsbilde eller en operasjonell status i tilnærmet sann tid, og oppdateres automatisk.
- Dokumenter som legges inn av brukere kan ikke overskrives eller endres av denne automatiske prosessen.
- Automatiske dokumenter kan ikke redigeres eller slettes av brukere
Automatiske dokumenter utvider bruksområdet til CMS kraftig, utover det å være en interaktivt dokumentarkiv. CMS kan dermed inkludere og vise tilstanden i omgivelsene. Dette er en kopling til det som kalles Internet-of-things.
I den foreliggende programkoden finnes modulen PubSubAdapter.py som kopler automatiske dokumenter til Publish-Subscribe distribusjon og MQTT-protokoll. På denne måten kan CMS være en del av et større nettverk av noder som samarbeider om å behandle sensor-information. Modulen createCMS doc.py gir et eksempel på hvordan MQTT-protokollen kan brukes for å opprette eller endre et CMS-dokument.
Legg merke til at programkoden i PubSubAdapter.py også tillater at tekst bli lagt til i eksisterende dokumenter, ved å søke etter tegnstrengen <!-- Insert --> i det eksisterende dokumentet. Denne tegnstrengen blir da erstattet med det nye innholdet, og dokumentet forøvrig blir bevart.
Egen kjøring, videre utvidelser og eksperimentering
Linken øverst i artikkelen laster ned et tar-arkiv av kildeteksten. Jeg anbefaler å kjøre CMS-tjeneren på en Linux-maskin, da den ikke er testet under Windows.
Last ned kildekoden i tar-format fra lenken i toppen av artikkelen, og hent frem cms.py i en editor. Du må se over definisjonene i begynnelsen av filen, spesielt om verdien av innerIP svarer til IP-adressene i ditt lokalnett.
Om du vil at CMS skal være tilgjengelig for omverdenen må du konfigurere routeren din med port forwarding, og kanskje satt opp dynamisk dns-navn. Dette omtales ikke her.
Før du starter CMS må disse programmene være installert:
- Programmene
pandoc, sqlite3 - Python-bibliotekene
web.py, pypandoc, paho-mqtt
Start så det hele med kommandoen
python3 cms.py 8080
8080 betegner TCP-porten som CMS skal bruke, om du endrer denne til 80 må du huske på å være root-bruker.
CMS har muligens ingen funksjoner som ikke finnes i andre samarbeidssystemer, men har det fortrinn at det er enkelt og kompakt, med kun noen hundre programsetninger. Systemets konstruksjon er dermed lett å forstå, utvide og endre. Det er derfor mitt ønske at de som laster ned og starter opp CMS vurderer utvidelser og nye funksjoner.