
794 total views, 2 views today
Anders Fongen, 2020
1. Innledning
Distribuerte Systemer er betegnelse på fagfeltet som beskriver hvordan programmer som kjøres i ulike datamaskiner (og på ulike steder) kan samarbeide om å løse oppgaver. Til forskjell fra andre modeller for programbehandling har distribuerte systemer noen egne kjennetegn [2]:
- Maskinene er løst koplet, dvs de deler ikke fysisk minne, men kommuniserer gjennom kanaler (f.eks. et nettverk).
- Kanalene mellom maskinene er feilbarlige, dvs. at trafikken gjennom kanalene er gjenstand for forsinkelser, endring, feil, bortfall og avlytting.
- Maskinene kan feile, krasje og restarte uavhengig av hverandre.
Disse problemstillingene hører hjemme på applikasjonslaget nettverksmodellen. Programkode som tilbyr tjenester og funksjoner knyttet til distribuerte operasjoner kan enten være en del av applikasjonen (anvendersystemet) eller skilt ut som separat programvare kalt mellomvare.
2. Hvorfor distribusjon?
Med ordet distribusjon sikter vi til anvendelser der flere maskiner kommuniserer over et nettverk for å løse en bestemt oppgave. Distribuerte anvendelser er en dagligdags ting i våre IT-omgivelser, f.eks. e-post og World Wide Web. Hvorfor har vi nytte av å lage distribuerte anvendelser? Vi kan peke på fire grunner i stikkordsform: datadeling, ressursdugnad, nettverksøkonomi og feiltoleranse.
2.1 Datadeling
Der hvor en datamaskin behandler data som skal deles mellom brukere, trenger alle brukerne en eller annen form for tilkopling til denne datamaskinen, dvs. en nettverksforbindelse. Over denne forbindelsen skal dataene fraktes frem og tilbake ettersom brukerne leser og endrer dataene. Figur 1 viser en distribuert anvendelse hvor brukere leser og skriver innholdet i det samme permanente lageret gjennom nettverksforbindelser. Den samme anvendelsen i en ikke-distribuert konfigurasjon ville ha krevd at alle brukerne hadde hver sin kopi av dataene. Lokale kopier av dataene har noen vesentlige ulemper:
- Endringer som gjøres av én bruker blir ikke synlige for de andre. Flere brukere kan komme til å gjøre uforenlige endringer på de samme dataene.
- Det totale lagringsvolumet i systemet øker.
Det sier seg selv at World Wide Web er avhengig av distribusjon. Litt av nytten av å lagre en nettside sentralt i en en webtjener er at den kan ajourholdes fortløpende av eieren. Volumet av dataene i World Wide Web er dessuten altfor stort til å lagres lokalt på en privat maskin.
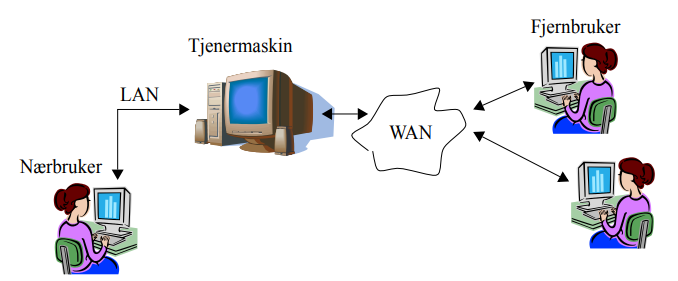
Figur 1: Eksempel på et distribuert system
Klient/tjener En distribuert konfigurasjon som baserer seg på et samarbeidsforhold hvor den ene parten «bestiller» og den andre parten «leverer», kalles klient/tjener. Anvendelser av datadeling som vist ovenfor er oftest utformet som klient/tjener, fordi det gir god kontroll med gyldigheten og tilgjengeligheten av de lagrede dataene. Brukere av en anvendelse er alltid klienter i en slik konfigurasjon.
Utstyrsdeling På samme måte som ved deling av data, finner vi også klient/tjener-anvendelser som tilbyr deling av utstyr. Vi kan f.eks. tenke oss at en kostbar fargeskriver ikke er en fornuftig investering dersom den kun skal betjene én bruker, men at den gjennom en klient/tjeneranvendelse kan benyttes av flere. I slike tilfeller er det tjeneren som kontrollerer skriveren og «leverer» utskrifter, mens brukerne er klienter som «bestiller» utskrifter.
2.2 Ressursdugnad
En annen type distribuert anvendelse er når én enkel maskin ikke har den ønskede behandlingskapasitet (minne, CPU-kapasitet eller permanent lager), men at det er mulig å forene ressursene i flere maskiner slik at de i sum har det. Eksempler på anvendelser som egner seg for ressursdugnad er:
Søking og sortering i store datamengder Der hvor vi vil søke etter en bestemt dataforekomst i et stort lager, kan oppgaven deles mellom mange maskiner som får oppgaven med å søke i hver sin delmengde av data. Deloppgavene er ikke avhengig av hverandre, og samordningsbehovet mellom maskinene er lavt.
Tilsvarende kan mange maskiner sortere hver sin del av en stor datamengde. Resultatet av disse delsorteringene kan til slutt flettes sammen for å fullføre sorteringen av hele datamengden.
Arbeidskrevende beregninger Visse matematiske problemstillinger krever enorm regnekraft, f.eks. knekking av kryptografiske operasjoner, «mining» av bitcoin, numeriske integral og rekkeutviklinger. Likeså krever simuleringsmodeller stor regnekraft for å oppnå nøyaktige resultater. Slike operasjoner kan ofte deles opp i mindre biter som kan spres på mange datamaskiner, og vi kan oppnå et raskere resultat.
Lastfordeling Mange tjenermaskiner kan være satt opp for å gi helt like tjenester og operere på de samme datakildene. Med et stort antall klienter kan den medfølgende store antall forespørsler spres jevnt på tjenermaskinene slik at hver av dem får en mindre arbeidsbelastning.
Arkiv av enorme datamengder På Internett finner vi eksempler på anvendelser som er distribuert for å spre lagringsbehovet over mange datamaskiner. Typisk er det filer som inneholder musikk og video som blir lagret, og spredningen på mange maskiner gjør det vanskelig å håndheve opphavsrettighetene på innholdet i filene.
Dataflyt-orienterte anvendelser I anvendelser hvor dataene behandles i flere «steg», og hvor resultatet fra ett steg er inndata til det neste, kan vi distribuere anvendelsen etter en «dataflyt»-modell. Da vil hver maskin behandle dataene i ett av stegene, og motta data fra maskinen som behandler forrige steg, og levere dataene (gjennom nettverket) til maskinen som behandler neste steg.
2.3 Nettverksøkonomi
Gjennom distribusjon kan vi også utnytte nettverksressursene bedre. Ved å:
Lagre data nær de brukerne som har størst overføringsbehov Et vanlig bruksmønster av lagrede data er slik at det er en liten del av brukerne som skaper mesteparten av trafikken ut og inn av lageret. Lagringstjeneren kan plasseres slik at disse brukerne har kort avstand, f.eks. gjennom et hurtig lokalnett. Da unngår vi å belaste kostbare WAN-ressurser med denne trafikken. Dette er den vanlige situasjonen ved mange nettsteder, hvor redaksjonen sitter nær web-tjeneren fordi de skaper mer trafikk mot den enn enkeltbrukerne gjør.
Unngå å overføre de samme dataene flere ganger Dersom mange av tjenerens brukere henter de samme dataene og overfører dem langs samme transportvei (rute i nettverket), da utnytter vi nettverkskapasiteten dårlig. I slike tilfeller kan det være gunstig å plassere en lokal kopi av dataene nærmere disse brukerne slik at de henter sine data fra den lokale kopien fremfor fra tjeneren selv.
Dersom den lokale kopien kun brukes til å støtte leseoperasjoner, dvs. operasjoner som ikke endrer innholdet av dataene i tjeneren, kaller vi den en cache. Dersom den lokale kopien kan endres (og de endrede dataene siden blir lagt tilbake i tjeneren) kalles vi tjeneren replikert eller et replikum (jfr. avsnitt 6.3 om replikeringstjenester).
Utføre behandling og presentasjon lokalt Volumet av de overførte data kan reduseres ved at dataene blir behandlet lokalt for presentasjon og kontroll:
- En grafisk fremstilling trenger ikke å overføres som et bilde. Den kan overføres som en serie av talldata, som klienten tolker og viser frem som et grafisk bilde. Klientmaskinen er da ikke legger bare en «skjerm», men en egen node i et distribuert system.
- Data som overføres fra en klient til en tjener skal være gyldige. Tjeneren vil nekte å godta «31. februar» som en dato, men da er det allerede brukt nettverksressurser på å overføre denne datoen til tjeneren. Klientprogrammet bør selv kontrollere så langt det lar seg gjøre at kun gyldige data blir sendt til tjeneren.
2.4 Feiltoleranse
Distribuerte anvendelser kan også innebære at flere maskiner gjør akkurat samme jobb, og behandler de samme dataene. Dersom én maskin krasjer eller produserer feil resultat, kan de andre maskinene sørge for å opprettholde normal drift.
Distribusjon kan også gjøre anvendelsen vår mindre sensitiv for nettverksfeil. Dersom veien frem til én tjener er utilgjengelig, kan vi forsøke en annen tjener som gjør samme jobben, og hvor veien dit er i normal virksomhet.
Bruk av redundans for å oppnå feiltoleranse er et fagfelt som bare delvis benytter distribusjon som virkemiddel, og vi vil derfor ikke behandle det separat. I en del sammenhenger er det derimot mulig å oppnå feiltoleranse som et «biprodukt» av distribuerte anvendelser, og det skal vi se eksempler på i avsnitt 6.3.
2.5 Ønskede egenskaper
Hvilke egenskaper er ønskelig ved et distribuert system? Vi har egenskaper som berører konstruksjons-/programmeringsfasen og konfigurasjon-/operasjonsfasen. Vi nevner her de viktigste:
Skalerbarhet En sentralisert datamaskin vil ha øvre grenser for sin behandlingskapasitet i form av inn-/ut-kommunikasjonshastighet til disker og nettverk, og i form av minnestørrelse og regnekraft. Et distribuert system har potensial til å flytte disse grensene etter hvert som nye noder legges til, men det er ingen selvfølge at dette lykkes. Skalerbarhet oppnås etter en grundig analyse av systemets arbeidsoppgaver og den valgte systemarkitekturen.
Interoperabilitet Et distribuert system vil bruke komponenter og programvare på en måte som skaper avhengighet til bestemte produkter og leverandører og som gjerne utelukker andre produkter. Om man f.eks. velger å basere seg på programvarekomponenter som bare kjøres på MS Windows vil vi siden ikke kunne inkludere noder som kjører Linux, IOS, MacOS eller Android. Dette reduserer fleksibiliteten og levetiden til det distribuerte systemet. Vi etterstreber derfor interoperabilitet, som betyr at systemet tillater komponenter fra ulike plattformer og programmeringsspråk å delta. Bruk av såkalt åpne standarder bidrar til dette. Åpne standarder er teknologi som alle kan benytte uten å ha tillatelse fra en «eier».
Single-system image Uttrykket betegner et distribuert systemer som «ser ut» som et sentralisert system. Perspektivet kan være fra programmereren, som kan skrive kode for et distribuert system akkurat som for et sentralisert system (bruk av stubs og skeleton bidrar til dette, se avsnitt 4.1). Perspektivet kan også være at systemets driftsprosedyrer er likt et sentralisert system med tanke på konfigurasjon, programvareinstallasjon, backup, feilsøking og berging etter krasj.
Beskyttelse av et system innebærer at angripere innenfor eller utenfor systemet ikke skal skade det distribuerte systemets integritet og tilgjengelighet. I et sentralisert system bygges beskyttelsen på sikkerhetsmekanismer i selve maskinvaren, som igjen forutsettes beskyttet mot fysiske angrep. Et distribuert system kan ikke bero på slike forutsetninger, og det er svært vanskelig å sikre seg mot at skadelig programvare («skadevare») tar kontrollen over en node og truer det samlede systemet med ondsinnet oppførsel. Beskyttelse av distribuerte systemer er et svært vanskelig problem som bare delvis lar seg løse med alminnelig tilgjengelig («COTS»-Commercial off-the-shelf) programvare.
3. Hva kjennetegner et distribuert system?
Vi vil nå diskutere noen problemer som kan oppstå i distribuerte anvendelser, men som ikke (eller sjelden) opptrer i sentraliserte anvendelser. Problemene oppstår bl.a. som følge av uunngåelige forsinkelser og feil i det nettverket som skal transportere dataene mellom partene i den distribuerte anvendelsen.
3.1 Løst koblede prosesser
Samarbeidende prosesser som kjører i samme datamaskin kan utnytte det faktum at de deler fysisk minne. Kommunikasjon og koordinasjon mellom prosessene kan gå via operativsystemet, som kan sette opp felles minneområder for dette formålet og sørge for at reglene for bruk av dette minneområdet overholdes. Bruk av felles minne gir svært liten forsinkelse og feiler aldri. Mutex og Semaforer er eksempler på koordinasjon gjennom felles minne.
I et distribuert system kan prosessene befinne seg i forskjellige maskiner og har ikke delt minne. Kommunikasjon og koordinasjon må skje gjennom meldinger i en kommunikasjonskanal, typisk IP-nettverket.
I prinsippet er det enkelt å lage nettverksprotokoller som gir mekanismer tilsvarende Mutex og Semaforer, men i praksis velger vi å lage koordinasjonsmekanismer med et høyere abstraksjonsnivå og som er tettere integrert i selve anvenderprogrammets operasjoner.
Et eksempel på slike koordinasjonsmekanismer kan være en enkel «test-and-set» operasjon: Dersom det finnes ledige seter i et fly, reserver ett sete og reduser antall ledige seter med én. Tett koblede prosesser vil bruke en Mutex til å låse denne variabelen, gjøre test-and-set og deretter låse opp. Dette er en ubrukelig strategi i et distribuert system fordi om en klient låser variabelen og siden krasjer, vil den forbli låst for alltid. I et distribuert system vil klienten heller sende en melding kalt «reservere ett sete», og motta en returmelding med «ok» eller «ikke mulig». mottakeren av meldingene (fra mange klienter) vil ha denne variabelen i sitt minne og sørge for nødvendig synkronisering, f.eks. ved å behandle én melding ferdig før den behandler den neste. Vi flytter derfor synkroniseringsbehovet fra klienten inn til tjeneren, noe som dessuten gjør operasjonen mer robust overfor krasj i klientnoden.
3.2 Ingen felles tilstand
Etter at en klient har sendt en forespørsel til en tjener, men den ennå ikke er mottatt av tjeneren, da er de to ikke enige om tilstanden i systemet. Klienten mener at operasjonen er påbegynt, mens tjeneren er av en annen oppfatning.
Den samme situasjonen vil opptre når operasjonen er fullført, og resultatet er underveis fra tjener til klient, og i alle andre former for meldingsutveksling i nettverket. Det er altså ikke mulig å betrakte systemets tilstand som en universell tilstand. Fra perspektivet til én av partene er systemet i en eller annen tilstand, men ikke nødvendigvis den samme som hva en annen part ser. Dette forholdet er illustrert i Figur 2.

Figur 2: Sender og mottaker er ikke i samme tilstand
Two army problem Det er faktisk ikke teoretisk mulig å oppnå enighet mellom to parter som er forbundet med en ikke-perfekt kommunikasjonskanal. Beviset presenteres som en fortelling om en hær som har tatt stilling på hver side av fienden, og budbringeren deres må springe gjennom fiendeland med risiko for å bli tatt til fange. Hæren kan bare overvinne fienden om de angriper samtidig, og sender budbringeren fra den ene til den andre siden med beskjeden «angrip ved daggry». Budbringeren kommer vel frem, men det vet ikke de som sendte ham, og de kan ikke vite om de har en avtale eller ikke. Derfor sendes budbringeren tilbake med beskjeden «melding mottatt», men nå er det motsatt side som ikke vet om budbringeren kommer frem og om de har en avtale eller ikke. Sånn kan de holde på med å sende budbringeren frem og tilbake i det uendelige uten å oppnå enighet, som vist på Figur 3.

Figur 3: The two army problem
I virkelige distribuerte systemer vil vi bruke tidsgrenser og kvitteringer for å øke sannsynligheten for at en avtale er inngått, men tidsgrenser kan heller ikke gi en sikker avgjørelse. Det skal vises litt senere i dette kapitlet.
Fordi partene følger regler (en protokoll) for hvordan operasjoner endrer systemets tilstand, vil dette ikke ha stor betydning unntatt i forbindelse med krasj.
3.3 Uavhengig krasj og feil
I en sentralisert anvendelse er programutføringen organisert slik at hele anvendelsen stopper opp dersom det skjer en alvorlig feil. Dvs. er det alltid hele anvendelsen som krasjer, ikke bare deler av den. Dette innebærer også at det er hele anvendelsen som starter opp under ett og at alle delfunksjoner starter opp i et veldefinert «startpunkt».
Annerledes blir det i en distribuert anvendelse, hvor maskiner som deltar i anvendelsen kan krasje og starte opp igjen, mens øvrige maskiner er i normal drift. Maskinen som starter opp en delfunksjon må derfor forholde seg til at den «fødes» til en verden med innloggede brukere, åpnede loggfiler, klienter som venter på svar fra den krasjede tjeneren m.m.
En tjener som krasjer midt under utføringen av en operasjon kan vise seg ved at den mottar en forespørsel fra en klient, men ikke sender noe svar tilbake. Når krasjet den?
- før operasjonen ble utført?
- etter at operasjonen ble fullført, men før meldingen tilbake til klienten ble sendt?
Klienten har ingen mulighet for å avgjøre dette. Dersom klienten velger å bestille operasjonen på nytt (kanskje fra en annen tjener) risikerer den å dublisere resultatet (to uttak fra en konto istedenfor ett). Alternativet er å ikke gjøre noenting, med den risikoen at operasjonen aldri blir utført.
Operasjoner i et distribuert system kan følge tre prinsipper:
- At-most-once semantics, hvor en operasjon utføres én eller null ganger, dvs. at systemets tilstand risikerer å forbli uendret ved feil som oppstår under operasjonen.
- At-least-once semantics, hvor operasjonen blir gjentatt dersom den iverksettende prosessen ikke mottar en kvittering på at den er korrekt utført.
- Exactly-once-semantics, hvor operasjonen er garantert å bli utført én gang.
Basert på diskusjonen ovenfor er det en beklagelig konklusjon at exactly-once-semantics ikke er mulig å oppnå!
En mulig løsning på dette dilemmaet er å lage den distribuerte anvendelsen med operasjoner som kan kjøres flere ganger uten at resultatet endres. Såkalte repeterbare operasjoner (også kalt idempotente) har denne egenskapen. De kan kjøres mange ganger, med det samme resultatet som om de bare ble kjørt én gang. Repeterbare operasjoner er noe som må planlegges fra bunnen av i anvendelsen, fordi det bl.a. påvirker hvordan datalagringen skal foregå. I en del anvendelser er dette ikke en mulig løsning, og da er det andre og mer kompliserte teknikker som må tas i bruk. Dette vil diskuteres i avsnitt 6.5.
Hvordan detekteres et krasj? De andre nodene i et distribuert system kan mistenke en node for å krasjet fordi det ikke er mulig å oppnå kontakt med den. Etter en viss tid kan så noden erklæres for krasjet, og en gjenopprettingsplan (crash recovery) settes i verk. Men hva er så «en viss tid» ? Som vist på Figur 4 blir dette en avveining mellom muligheten for at det er forsinkelse i det underliggende nettverk, at noden er opptatt med andre oppgaver og ikke har rukket å svare, og den forsinkelsen som oppstår i systemet før en gjenopprettingsplan kan iverksettes.
Figur 4: Avveininger ved tidsgrenser for krasjdeteksjon
Med et underliggende nettverk uten garantert leveringstid (slik tilfellet er i alle IP-nettverk) synes det klart at sikker feildeteksjon ikke er mulig i IP-nettverk. Det betyr at mekanismer for gjenoppretting av krasj (f.eks. ved å ta i bruk en reservenode) må ta høyde for at den antatt krasjede noden våkner til liv igjen.
3.4 Ingen felles tidsangivelse
Det er ikke mulig for partene i en distribuert anvendelse å ha eksakt samme oppfatning av hva klokka er. De innebygde klokkekretsene i maskinvaren vil, som alle andre klokker, ha en viss avdrift, og vil vise ulik tid etter hvert. Vi kan velge ut én maskin som «urmester» som kan sende meldinger til andre maskiner med riktig tid, men disse meldingene vil ha en forsinkelse som er umulig å forutse nøyaktig, derfor kan vi heller ikke beregne nøyaktig tid ut fra disse meldingene. Vi kan lage mekanismer som reduserer avviket mellom klokkene, men situasjonen forblir den samme i praksis, nemlig:
Kronologiske hendelser kan synes å ha skjedd i motsatt rekkefølge.
Et enkelt eksempel er når flere maskiner bruker en felles tjeneste for å loggføre hendelser. Meldingene som sendes til loggføring er tidsstemplet med klokkeinformasjon fra hver enkel klientnode. Hendelsesforløpet kan se slik ut:
- Node A utfører en operasjon og sender resultatet til node B samtidig som hendelsen loggføres.
- Node B viderebehandler det mottatte resultatet og loggfører dette.
- Fordi B’s klokke har saknet litt, er tidsstemplet fra B i loggen et tidligere tidspunkt enn tidspunktet logget fra A, til tross for at operasjonen hos B er en konsekvens av operasjonen i A.
Systemet i dette eksempelet viser en tilsynelatende motsetning mellom kausalitet og kronologi, dvs. at årsaken skjer etter virkningen. Et annet eksempel er at Node B kun vil behandle «ferske» resultater fra A, og vil derfor forkaste resultater med et tidsstempel eldre enn en viss deadline. Dersom A’s klokke er saknet vil selv ferske resultater bli forkastet av B, og systemet vil slutte å virke som planlagt.
Generelt gjelder dette for distribuerte systemer at der et tidsstempel påføres i én node og kontrolleres i en annen vil klokkedrift kunne hindre systemet å fungere etter hensikten. Klokkedrift vil også skape sikkerhetshull, fordi tidsstempler inngår i mange sikkerhetsprotokoller.
4. Hvordan konstrueres et distribuert system?
Vi kan betrakte et distribuert system som et samfunn av prosesser som ber hverandre om hjelp for å løse en felles oppgave. Den som spør, kalt klienten, sender en forespørsel til en annen prosess (kanskje i samme node, kanskje i en annen). Mottakeren, kalt tjeneren, behandler forespørselen og sender et svar. En slik hendelse kaller vi en transaksjon, og kan kategoriseres ut fra noen av sine egenskaper:
- Unicast/Multicast/Anycast Sender klienten forespørselen til én bestemt mottaker (unicast), til mange mottakere (multicast) eller til én av flere mulige (anycast)?
- Synkrone/Asynkrone kall Er klienten inaktiv (blokkert) mens den venter på svar (synkrone kall) eller fortsetter den utføringen og behandler svaret når det engang ankommer (asynkrone kall)?
La oss nå se på noen ulike kategorier av transaksjoner som kan finne sted mellom distribuerte prosesser, nemlig Remote Procedure Calls, Publish-Subscribe og Tuplespace.
4.1 Remote Procedure Calls
Den enkleste transaksjonen mellom to distribuerte prosesser kalles Remote Procedure Call (RPC). Den benytter unicast adressering og synkrone kall. Således ligner den på vanlige metode- eller funksjonskall slik vi er kjent med i de fleste programmeringsspråk. Inndata til tjeneren (det vi i et programmeringsspråk kaller aktuelle parametre) legges ved i forespørselen, og returdata legges i svarmeldingen. Evt. feilmeldinger fra tjeneren legges også i svarmeldingen.
Til forskjell fra lokale funksjonskall må klientene nå ha programkode som takler feil som oppstår under meldingsoverføringen, typisk om svaret fra tjeneren ikke mottas innen en tidsgrense. Dette høres ut som en enkel ekstrajobb, men det krever tvert imot at hele programflyten designes med feilhåndteringsteknikker på alle steder der hvor RPC utføres.
De fleste programmeringsspråk har hjelpebiblioteker som lar programmeren benytte seg av RPC. I sin enkleste form må klienten vite adressen til tjenerens nettverksadresse (IP-adresse), i andre tilfeller må klienten tilegne seg denne informasjonen først.
HTTP-protokollen egner seg utmerket for RPC-formål. Parametere for operasjonen (inndata) kan enten legges som en del av tjenestens URL, eller som data i «nyttelasten» til meldingen. Returdata eller feilmeldinger legges i HTTP-svaret. Bruk av HTTP er støttet i praktisk talt alle programmeringsspråk, så RPC basert på HTTP kan benyttes av «alle». Standardprotokoller for RPC, kalt XML-RPC, REST og SOAP, bruker HTTP som underliggende meldingstjeneste.

Figur 5 – En HTTP RPC-operasjon vist i Wireshark
Figur 5 viser en Wireshark-dump av en RPC-transaksjon som benytter HTTP-protokoll med parametre (rødt) og returverdier (blått) kodet med såkalt JSON-notasjon. Headerlinjene i HTTP-meldingene burde være kjent for leseren.
Stubs og skeletons Likheten mellom RPC og funksjonskall gjør at man introduserer egne programvarekomponenter på klienten og i tjeneren slik at en RPC-operasjon skrives akkurat som et funksjonskall i programmeringsspråket. Slike komponenter kalles stub og skeleton og er vist på Figur 6. De blå firkantene er anvenderkoden, som gjennom operasjonene 1, 10, 5 og 6 kommuniserer som om de kaller/implementerer funksjonen
result = sum(p1,p2)
mens stub oversetter dette kallet til en melding i JSON-format slik som vist med Wireshark i Figur 5, vil skeleton oversette meldingen til et virkelig kall til funksjonen ovenfor.

Figur 6: En RPC-operasjon med bruk av stub og skeleton
Langs pilene 2, 9, 4 og 7 går altså HTTP-meldinger med innhold i JSON-format, mens pilene 3 og 8 er TCP-segmenter og IP-pakker som krysser det virkelige nettverket.
Bruk av stubs og skeleton bidrar til det vi kaller transparens, hvor det distribuerte systemet ser ut som ett sammenhengende system, og vi kan programmere det som om det var et ordinært program med separate programmoduler. Jfr. «Single System Image» i avsnitt 2.5.
4.2 Publish-Subscribe
Publish-Subscribe (PS) er en modell hvor klienten ber om å få abonnere på en bestemt type informasjon. Tjeneren lagrer denne forespørselen sammen med informasjon om klientens nett-adresse og port. Når slik informasjon blir tilgjengelig (f.eks. ved at andre klienter publiserer informasjon) vil den sende (deliver) informasjonen som meldinger til alle klienter som abonnerer på slik informasjon. Siden meldingen kan ha mange mottakere kan tjeneren benytte seg av multicast adressering der det er praktisk.
Etter at en klient har bedt om å få abonnere vil den ikke stoppe mens den venter på levert informasjon. Den vil fortsette sin utføring og behandle publiserte svarmeldinger etterhvert som de ankommer ved at bestemte event-funksjoner utføres. PS bruker altså asynkrone kall og multicast adressering (der det er mulig).
En abonnementsforespørsel vil spesifisere hva slags informasjon som er ønsket. Det betyr at et PS-system må ha en omforent måte å uttrykke dette på, og en måte å inspisere informasjon på med tanke på å finne hvilke abonnementer den passer til. Informasjonstema er en vanlig teknikk, hvor temaene kan være hierarkisk organisert slik at abonnementet kan være bredt (f.eks. alt om fotball) eller smalt (alt om fotball i Norge i 2. divisjon og høyere). Alle som publiserer data må påføre riktig tema, ofte i form av «merkelapper» på informasjonen (kalt metadata).
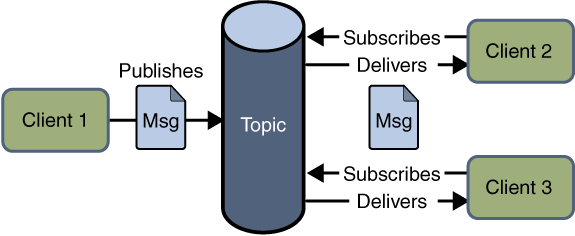
Figur 7: Eksempel på distribusjon av data med Publish-Subscribe-modellen
Figur 7 viser hvordan tjeneren (vist med ordet «topic» ) lar klientene både publisere og abonnere på informasjon, selv besørger den kun lagring og formidling.
En annen måte å opprette et abonnement på er ved å spesifisere krav til innholdet. Om det f.eks. publiseres numeriske data på en strukturert form kan klienten spesifisere at ett bestemt tall skal være innenfor et bestemt område, at en posisjon skal være innen et polygon, eller at tekstdata skal ha et bestemt innhold. Her vil ikke tjeneren inspisere metadata, men selve informasjonsinnholdet. Den økede frihetsgraden i et slikt system gjør tjenerens konstruksjon mer komplisert [1].
Publish-Subscribe distribusjon skaper helt andre forutsetninger for å bygge en anvendelse som i større grad fokuserer på klientenes samarbeid, siden de nå behandler data som i større grad kommer fra andre klienter fremfor å være fremskaffet av tjeneren. Et annet aspekt med PS er at klientene nå ikke styres av sin egen programkjøring, men av hendelser som formidles i form av publisert informasjon. En klient vil kople sin programlogikk til mottatt informasjon fremfor sine egne forespørsler etter et mønster som vi kalte asynkrone kall i innledningen til dette avsnittet. En slik konstruksjon forbedrer også systemet skalerbarhet, fordi en økt pågang av klienter og økt informasjonsmengde vil gi en gradvis og elegant økning i responstiden uten at systemet får «forstoppelse».
4.3 Tuplespace
En tredje transaksjonstype som vi vil behandle er basert på et felles lager av informasjonselementer kalt tupler, og regler for hvordan de legges inn og hentes ut av lageret. Prinsippene for en tuplespace (TS) er ganske enkle:
- En tuple består av en ordnet samling av felt, hvert felt har en verdi og en type.
- En template minner om en tuple, men feltene kan ha verdien NULL, dvs. ingen verdi.
- En template passer til en tuple dersom (a) den har samme antall felt, og (b) hvert felt i template har enten verdien NULL eller samme verdi og type som feltet på samme posisjon i tuple.
- En klient kan skrive en tuple til en tuplespace. Operasjonen returnerer ingen data.
- En klient kan hente en tuple ved å bruke en template som parameter. Dersom det finnes én eller flere tupler i space som passer til template-parameteren returneres en slik tuple til klienten.
Henteoperasjonen i punkt 5 har videre tre aspekter ved seg:
- Konsumerende/ikke-konsumerende Tuplen som returneres kan enten fjernes fra tuplespace eller forbli der som kandidat for nye gjenfinningsoperasjoner. En tuple vil aldri bli returnert til flere klienter som bruker den første varianten (tuplen er atomisk)
- Blokkerende/ikke-blokkerende Dersom det ikke er noen tupler som passer til templaten kan klienten settes til å vente på at noen andre skriver inn en slik tuple, eller returnere straks uten returverdi.
- Multi/enkel returverdi Dersom det er flere tupler som passer til en template kan enten alle returneres, eller kun én av dem.
Med disse enkle mekanismene kan en tuplespace støtte et bredt spekter av kommunikasjons- og synkroniseringsmønstre: En blokkerende gjenfinningsoperasjon kan la en klient utføre kode som en respons på andres skriveoperasjoner. Mange klienter som gjør en konsumerende henteoperasjon kan la tupler representere «arbeidsordrer» og dermed fordele arbeidsmengden mellom seg (ressursdugnad). Ved bruk av ikke-konsumerende gjenfinning kan tuplespace være en enkel database med en fleksibel søkemekanisme.
Figur 8 viser en tuplespace med noen i tupler i seg, samt to klienter som gjør henholdsvis en skriveoperasjon med en tuple som parameter, og en henteoperasjon med en template som parameter.
Figur 8: En tuplespace vist med en skrive- og en hente-operasjon
En tuplespace-tjener en en enkel konstruksjon og kan programmeres med så lite som 500 programlinjer. Problemet er å gjøre den skalerbar. Det er vanskelig å splitte opp en tuplespace på flere tjenere [9], og gjenfinningsoperasjonene krever at man inspiserer hver eneste tuple som skal passe til en template, og omvendt.
Disse tre modellene for transaksjonsmønstre kan også sees i et annet perspektiv: de er henholdsvis kontrolldrevet, eventdrevet og datadrevet.
Kontrolldrevet innebærer at handlingene til en node er bestemt av flyten i dens kontrollprogram, dvs. alle transaksjoner følger av programmets egne beslutninger. Vi kaller dette også for en synkron utføring, det brukes synkrone RPC kall for transaksjonene. En web-browser kan sies å være kontrolldrevet. Et kontrolldrevet node responderer på kommandoer og behov fra brukeren eller lokale prosesser, og koordinerer seg i mindre grad med andre noder.
Eventdrevet innebærer at nodens program i stor grad styres av hendelser som andre noder rapporterer om, dvs. at programmet responderer på hendelser fremfor å følge sin egen programflyt. Publish-Subscribe modellen er et eksempel på en eventdrevet modell, hvor nodene kommuniserer og koordinerer seg med hverandre gjennom å publisere hendelser.
Datadrevet innebærer at nodene reagerer på endringer i en felles database, f.eks. slik vi ser i en tuplespace. Der kan nodene respondere på at tupler skapes eller slettes, og det kan skje på basis av svært fleksible seleksjonsmekanismer. I et datadrevet system kommuniserer og koordinerer nodene seg i mellom ved å endre tilstanden i et felles datalager.
4.4 Peer-to-peer
Vi har tidligere i dette avsnittet presentert RPC, PS of TS som mulige transaksjonsmønstre, hvor alle tre baserer seg på tilstedeværelsen av en tjener. Svikter denne tjeneren så svikter hele systemet, evt. inntil man har fremskaffet en ny tjener.
Et distribuert system som er helt uten sentrale tjenerfunksjoner kalles et peer-to-peer system (p2p), fordi alle nodene (nå blir det misvisende å kalle dem klienter) handler direkte med hverandre. Nye noder kan komme til, andre kan falle fra, men p2p-systemet fungerer og tilbyr tjenester og informasjon basert på hvem som deltar til enhver tid. Det fremstår dermed som svært robust, siden linker og noder kan krasje og restartes uten at systemet, sett under ett, svikter. Et eksempel på et p2p-system er vist på Figur 9. Legg merke til at trafikk mellom D og E går via B, slik at dette systemet pådrar seg en rutingproblematikk.

Figur 9: Eksempel på peer-to-peer distribuert system
Tankegangen minner litt om adaptiv ruting på nettlaget, hvor overflødige linker kan forbedre fremkommeligheten i nettverket ved at de skaper alternative veier mellom to noder (som ACE og ABE på Figur 9). I et p2p-system kan man tenke seg at mange noder kan tilby de samme tjenestene slik at en annen node med stor sannsynlighet kan finne minst én av disse.
Et vanlig eksempel på et p2p-system er et som tilbyr fildeling. Noder som ønsker å dele en fil kan sende den til noen av sine nærmeste naboer. Andre naboer som ønsker å laste den ned kan rette en forespørsel om dette til én av disse naboene, eller få filen bitvis fra flere naboer. Tanken er at trafikken spres over mange linker og dermed utnytter nettverkskapasiteten bedre, og at noder kan forlate p2p-systemet (f.eks. krasje) uten konsekvenser så lenge andre noder er på og har filen lagret.
Når nye noder legges til systemet vil både informasjonsmengden og antall transaksjoner øke, men de nye nodene vil også øke den totale beregnings- og kommunikasjonskapasiteten, noe som hevdes å gjøre et p2p-system selvskalerende [3, avsnitt 2.5 side 169].
P2p-systemer bygger på denne enkle filosofien med bruk av redundans for å kompensere for mangelen av en sentral tjener. For at eksemplet over skal kunne programmeres til et kjørende system kreves det at to underliggende problemer blir løst:
Peer discovery innebærer at en node må vite hvilke naboer som er aktuelle å kontakte i forbindelse med en operasjon (opplasting eller nedlasting). Hvordan skal noden få informasjon om noder som kan kontaktes og siden gjøre et utvalg av disse? Disse nodene er ikke nødvendigvis naboer, så det er også aktuelt å måtte bygge rutingtabeller i denne forbindelse.
Information discovery innebærer at noden må skaffe seg kunnskap om den informasjonen som finnes i systemet, f.eks. i form av en filkatalog som brukeren av den noden kan søke i.
Begge disse to behovene ovenfor kan løses ved å fortelle «alt til alle», dvs. oversvømme (flooding) nettverket med discovery-informasjon om noder og lagret informasjon. Trafikkmengden som vil skapes av en slik løsning kombinert med hyppigheten av ut- og innmeldinger fra noder i systemet vil forbruke uforholdsmessig mye av nettverkskapasiteten.
Det finnes metoder for å beregne hvilken node som skal lagre et bestemt informasjonselement, f.eks. kalt Distributed Hash Tables (DHT). Systemer basert på DHT løser altså noe av information discovery problemet på p2p-vis, men tillater bare direkte oppslag på et element som man kjenner navnet på, og tilbyr ingen søke- eller opplistingsfunksjon [4].
Hybrid p2p Enkelte p2p-systemer, f.eks. Napster og BitTorrent [5] benytter seg av en konstruksjon hvor discovery-funksjonene løses av en (eller et fåtall) tjenere, mens selve dataoverføringen foregår etter et p2p-mønster. Et slikt hybridsystem gir bedre brukerbetjening, men er naturligvis sensitiv for tjenerkrasj. I praksis blir konsekvensene av et tjenerkrasj dempet ved at nodene lagrer data fra tidligere forespørsler som kan gjenbrukes i en viss periode.
Manglende sikkerhetsmodell Det er vanskelig å beskytte et p2p-system mot cyberangrep. Det er i praksis umulig å skille mellom konstruktive og destruktive bidrag fra nodene i systemet uten å pålegge dem strenge krav til hardware-konfigurasjonen i form av bestemte sikkerhetsmoduler [6]. Tradisjonelle teknikker for ende-til-ende sikkerhet kan ikke brukes i miljøer hvor man ikke kommuniserer med en kjent motpart, noe som er tilfellet også i systemer som er eventdrevet eller datadrevet.
Manglende forretningsmodell I et p2p-system finnes ingen leverandør, og heller ingen som sikrer at systemet er operativt. Dersom nodene ikke har samme eier vil det heller ikke være et sterkt interessefellesskap for å holde systemet i god form (fenomenet er kalt tragedy of the commons). Mangel på en sentral ansvarlig aktør gjør p2p-arkitektur mindre attraktiv for bruk i kommersielle eller samfunnskritiske anvendelser.
5. Tjenesteorientert arkitektur
Tjenesteorientert arkitektur (eng: Service Oriented Architecture – SOA) er et konstruksjonsprinsipp med en ganske vid definisjon: Enhver handling som utføres på vegne av en annen regnes som en tjeneste. En slik definisjonen vil inkludere f.eks. nettverkskomponenter som svitsjer og rutere i begrepet «tjenere», noe som ikke skjer i praksis [8].
SOA, slik dette begrepet vanligvis gis innhold, betyr at man bygger et system med noder som inngår i klient-tjener forhold, og at tjenerne selv er klienter i forhold til andre tjenernoder. Vi kan forestille oss disse relasjonene som «skall» på en løk som pakker inn stadig mer grunnleggende tjenester. I litt eldre litteratur finner man begrepet «N-lags arkitektur» som referer til det samme prinsippet.
SOA skiller seg fra tradisjonell klient-tjener (og N-lags) arkitektur i tilstedeværelsen av tjenesteoppdagelse (eng: service broker eller service discovery). Dette er en tjeneste hvor klienten kan formulere sitt behov for en tjeneste og få i retur en liste over tjenerkandidater som klienten kan velge fra. Tjenesteoppdagelsen vil på sin side være avhengig av at disse tjenerkandidatene på forhånd har publisert opplysninger om sine tjenester.
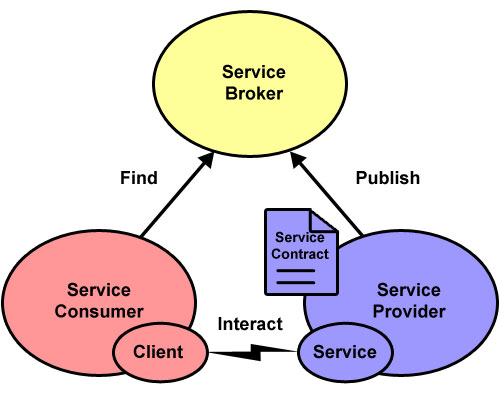
Figur 10: Prinsippene ved Service Oriented Architecture
Figur 10 viser hvordan klient, tjener og tjenesteoppdagelse danner en trekant med transaksjoner vist med engelske betegnelser. Tjeneren må først publisere (publish) sine tjenester før klienten kan oppdage (find) dem og siden kalle (interact) dem.
Tjenesteoppdagelse er et omfattende tema som vil bli separat behandlet i avsnitt 6.1
Interoperabilitet SOA-prinsippene legger stor vekt på at klienter og tjenere skal kunne bruke alle slags programmeringsspråk og operativsystemer, derfor er mekanismene for utveksling (protokoller og formkrav til innholdet) av forespørsler og retursvar utformet for å være arkitekturnøytrale. En mye brukt standard for formatering av innholdet i meldinger er SOAP – Simple Object Access Protocol, som igjen er basert på XML – eXtensible Markup Language.
SOAP-meldinger inneholder kun skrivbar tekst, men har en litt komplisert struktur. De fleste programmeringsspråk har kodebiblioteker for å skrive og tolke SOAP-meldinger i likhet med stub- og skeleton-modulene beskrevet i avsnitt 4.1. Uten slike kodebibliotek er det allikevel mulig å lage og tolke SOAP med vanlige funksjoner for behandling av tegnstrenger som finnes i alle språk.
Disse egenskapene ved SOAP bidrar til interoperabilitet, som er en egenskap man ønsker å oppnå i distribuerte systemer. Det må også nevnes at andre meldingsformater som benytter kun tekstrepresentasjon, som f.eks. JSON og andre XML-baserte formater, vil ha de samme egenskapene.
Bare RPC-tjeneste? Fra beskrivelsen over kan det virke som om tjenesteorientering forutsetter bruk av RPC-mønster og synkrone kall. Dette er ikke tilfelle, Publish-subscribe er fullt mulig å bruke i de tilfelles det er fornuftig. Det er derimot slik at de åpne SOA-standardene knyttet til Publish-subscribe er dårligere utviklet og med flere åpenbare svakheter, f.eks. knyttet til beskyttelse og sikkerhet [7]. Derfor kan bruk av PS i SOA medføre mer manuelt programmeringsarbeid.
5.1 As-a-service
Tjenesteorientering er et prinsipp for arbeidsdeling mellom distribuerte noder, den gir ingen føringer for tjenestens art. Om man tenker seg en applikasjon delt opp i mange lag sett fra brukeren og «nedover» kan f.eks. disse lagene identifiseres:
Brukerdialog – presentasjonslogikk – adgangskontroll – forretningslogikk – database
Mellom alle disse lagene er det fullt mulig å legge et tjenesteorientert grensesnitt, dvs. at oppgavene på hver side utføres av ulike maskiner. Debatten rundt tjenesteorientering har derfor identifisert en rekke mønstre for hvilke deler av en distribuert system som kan tilbys som en tjeneste. Alle disse mønstrene har ordene «as-a-service» til slutt, og de viktigste (og mest fornuftige) vil presenteres her:
Storage-as-a-service betyr at lagringsbehovet til en anvendelse delegeres til en tjeneste. Dette kan skje ved at hele filsystemet flyttes dit, slik tilfellet er med f.eks. Dropbox. Det kan være at tjenesten tilbyr en relasjonsdatabase og at klienten kaller denne med SQL-setninger, eller at tjenesten tilbyr lesing og skriving av enkeltfiler gjennom WebDav-protokollen.
Software-as-a-service er at hele anvendelsen blir tilbudt som en tjeneste i form av et brukergrensesnitt, gjerne gjennom en web-leser. Office365 fra Microsoft, Google Docs, FIF osv. er eksempler på dette mønsteret.
Platform-as-a-service tilbyr et operativsystem som en tjeneste, og kunden kan installere alle slags applikasjoner og kjøre dem etter eget behov, kanskje som en webtjener. En annen variant er hva vi kjenner som webhotell, der plattformen er en webtjener som kunden kan fylle med websider og programvare.
Infrastructure-as-a-service er en modell hvor kunden disponerer virtualisert maskinvare og kommunikasjonslinker, og installerer operativsystem, applikasjoner, rutingtabeller osv. Vi kan se for oss at kunden ønsker å tilby sine tjenester på ulike steder av verden, og ønsker derfor kommunikasjon mellom disse stedene.
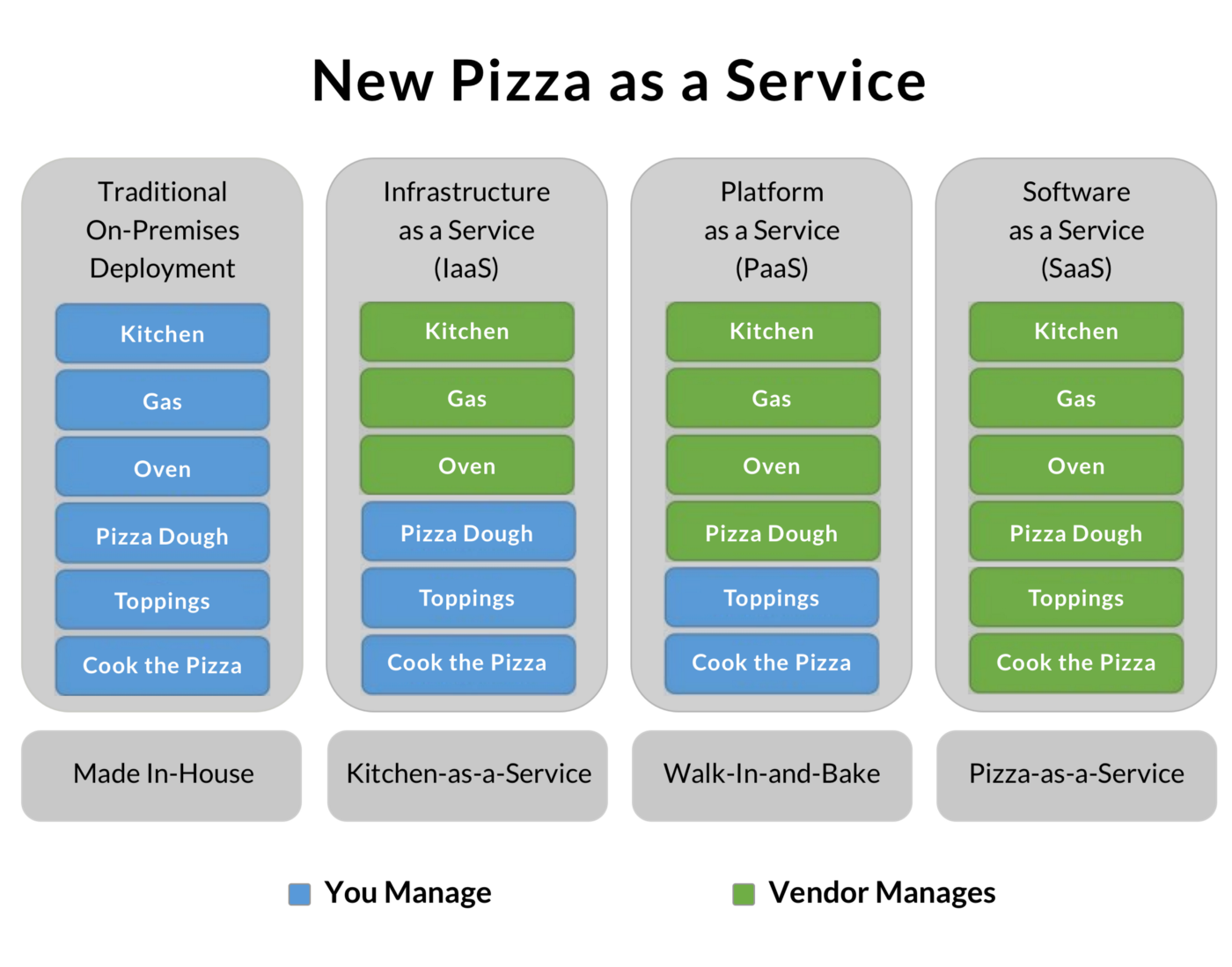
Figur 11: Inndelingen ved ulike «as-a-service» konfigurasjoner
Figur 11 viser hvordan «as-a-service» -mønstrene kan tenkes anvendt på et pizzabakeri. Vi ser her hvordan Software-as-a-service er en mer omfattende leveranse enn Infrastructure-as-a-service.
As-a-service mønstrene kan naturligvis bygge på hverandre som i en lagdelt modell. En leverandør av Software-as-a-service kan selv være kunde hos en leverandør av Platform-as-a-service, som igjen kan være kunde av en Storage-as-a-service.
5.2 Skybaserte tjenester
Skybasert databehandling (eng: cloud computing) er en forretningsmodell mer enn en arkitekturmodell. I bunnen ligger en streng deling mellom klient og tjener, og klienten ser bare det «ytterste laget av løken». Fra klientens perspektiv er dette identisk med hva som ble kalt «N-lags arkitektur» i avsnitt 5.
Skyen er et sted hvor man tenker seg at det er ubegrensede ressurser som tjenestetilbydere kan leie etter som behovene endrer seg. Skyen er organisert på en måte som gjør det mulig på noen timers varsel å f.eks. hundredoble kapasiteten som disponeres av en leietager. Dette kan gjelde både maskinkraft, lagringskapasitet og kommunikasjonskapasitet.
Virtualisering Innredningen av skyen krever teknologi for å dele og forene maskin- og nettverksressurser mellom tjenestetilbyderne. Denne teknologien vil gjøre utstrakt bruk av virtualisering, som innebærer at maskinvare blir etterlignet av en hypervisor (programvare) slik at flere operativsystemer kan kjøres side om side i samme fysiske maskin og fremstå som flere fysiske maskiner. De virtuelle maskinene kan kjøres med ulik tilgang til underliggende ressurser og med ulik prioritet tilpasset til det aktuelle behovet.
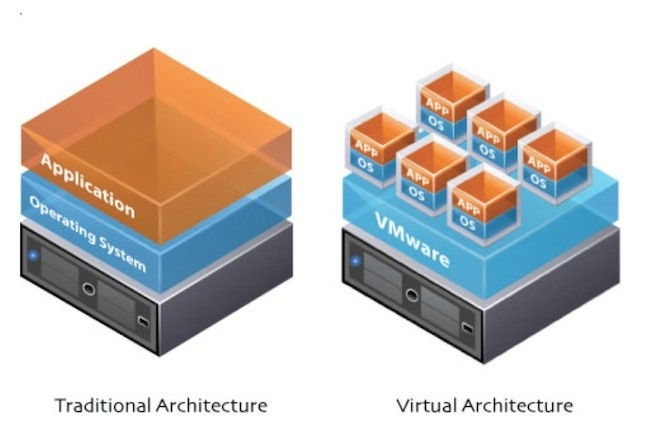
Figur 12: Forskjellen på tradisjonell OS-installasjon og OS inne i en hypervisor
Figur 12 viser til venstre en tradisjonell arkitektur hvor én maskin kjører ett operativsystem og en eller flere applikasjoner. Til høyre vises hvordan hypervisor-produktet VMware tillater at mange operativsystemer installeres side om side i hver sin virtuelle maskin med hver sine applikasjoner oppå. Oftest vil hypervisoren ikke kjøres direkte på maskinvaren, men oppå et operativsystem. To viktige fordeler med bruken av hypervisor er fleksibilitet og sikkerhet. Applikasjoner som kjører i ulike virtuelle maskiner er sterkere isolert fra hverandre enn prosesser som kjører i samme operativsystem, noe som gjør systemet mer robust mot feil og angrep.
Tilsvarende kan moderne nettverkskomponenter i stor grad styres av programvare som lar ruter i nettverket fremstå som private linker. Ett fysisk nettverk kan inneholde mange virtuelle nettverk ved bruk av egnet teknologi. Slike mekanismer går under navnet VPN – Virtuelle Private Nett, og teknologier som VLAN (Virtual Local Area Network), MPLS (MultiProtocol Label Switching) og SDN (Software Defined Networking) er mye brukt i implementasjonen av VPN.
For både virtualisering av maskinvare og nettverk byr skybasert databehandling på spesielle problemstillinger knyttet til skalerbarhet, fleksibilitet, styring og beskyttelse.
En sky med store ressurser, mange kunder og høye krav til hurtig omkonfigurering må kunne styres med et lavt personellbehov og må bero på automatisering (ofte kalt orkestrering eller koreografering).
6. Viktige støttetjenester for distribuerte systemer
Organiseringen og styringen av et distribuert system byr på mange særlige problemstillinger som ikke oppstår i et sentralisert system, men som til gjengjeld er ganske likelydende blant distribuerte systemer. Disse problemstillingene kan være knyttet til:
- Hvordan oppdage ressurser og aktører som utgjør det distribuerte systemet?
- Hvordan sørge for at nodene har noenlunde like klokker?
- Hvordan sørge for at nodene informerer hverandre i ordnede former, og at alle har fornuftig og oppdatert informasjon tilgjengelig?
- Hvor befinner jeg meg, og hvor er de andre nodene jeg samarbeider med?
- Hvordan sørge for at noder som krasjer, kan gjenoppstå slik at de fortsatt kan delta i systemets aktiviteter?
- Hvordan sørge for at aktørene i et distribuert system kan identifiseres og gis rettigheter i henhold til sine autorisasjoner?
Det ikke nødvendig at hvert distribuerte system løser disse problemstillingene selv, derfor overlates de til såkalte støttetjenester som løser dem på velprøvde og standardiserte måter.
Støttetjenester kjennetegnes altså ved at de ikke formidler nyttedata, men metadata og funksjoner som er nødvendig for systemets operasjon. Tjenestene kan tilbys via nettet i separate noder, eller som programvarebibliotek i klientnoden.
En del populære støttetjenester vil nå bli gjennomgått:
6.1 Oppdagelsestjenester
Oppdagelsestjenester (eng. Discovery services/-protocols) betegner prosesser for å finne adresser til tjenere, finne navn på deltakernoder, finne lister over tilgjengelige tjenester, finne filer og dokumenter i et lager osv. Noen oppdagelsestjenester er velkjente, som f.eks. Domain Name Services (DNS) og Address Resolution Protocol (ARP), som ikke vil beskrives nå. Rutingprotokoller på nettlaget er også et eksempel på en oppdagelsestjeneste. Oppdagelsestjenester kan kategoriseres på følgende måte:
Peer discovery som har til oppgave å kartlegge andre aktører/noder i systemet, og å finne deres navn, egenskaper, oppgaver og roller. DHCP, ARP, DNS og ActiveDirectory er eksempler på slike tjenester.
Link discovery har til oppgave å kartlegge hvilke kommunikasjonslinker som er til disposisjon, og å bestemme deres egenskaper (hvem leder linken til, hva er dens kapasitet, forsinkelse, feilrate m.m.). Link discovery gjøres ofte ved å sende prøvemeldinger langs en link og vente på et svar fra en node i andre enden.
Service discovery (norsk: tjenesteoppdagelse) er kartleggingen av hvilke tjenester som er mulig å bruke og som dekker et spesifikt behov. En node kan ha et behov for f.eks. en karttjeneste som viser nedgravde rørledninger. Noden kan formulere en egnet spørresetning og oppnå en liste over kandidater som tilbyr dette. Svaret kommer i en form som (1) lar noden gjøre et informert valg blant kandidatene, og (2) viser noden hvordan tjenesten skal kalles. Målet med tjenesten er at utforming av spørresetning, valg av kandidat og påfølgende kall til tjenesten skal kunne foregå automatisk uten å involvere programmerer eller operatør, noe som krever en nøyaktig og formalisert utforming av spørsmål og svar. Tross mye forskning på feltet er det sjeldent man finner helautomatisk bruk av oppdagelsestjenester. Vanlig er det derimot at del (2) av svaret, som vedrører kall til tjenesten, resulterer i en automatisk generering av en stub-modul (se avsnitt 4.1) ved hjelp av en formell tjenestekontrakt (eng. service contract). Innen SOA-området finnes vi slike kontrakter på formen Web Services Description Language (WSDL) som er godt integrert i mange programutviklingsverktøy.
Information discovery er på sin side kartleggingen av informasjonsressurser. Dersom informasjonen er bilder og tekst, og spørringen utformes av en person så minner dette om hva en søkemotor (f.eks. Google, Bing) tilbyr på Internet. I distribuerte systemer kan informasjonsressursene være fordelt mellom nodene, og det er derfor nødvendig å kartlegge disse ressursene med andre teknikker enn hva en søkemotor benytter seg av (se avsnitt 4.4 om p2p-distribusjon).
Katalogbasert eller kringkastingsbasert? De fire oppdagelsestjenestene nevnt over har det til felles at de kombinerer en innsamlingsfase med en seleksjonsfase. Her kan man tenke seg to hovedkategorier av mekanismer: (1) En innsamlingsfase som bygger opp en katalog basert på at nodene selv publiserer informasjon om sine lokale ressurser, eller at et agentprogram fremskaffer disse opplysningene. Siden vil klientforespørsler løses ved å inspisere denne katalogen, se Figur 13. (2) En klientforespørsel resulterer i en kringkastingsmelding til alle nodene i systemet. Alle nodene sjekker forespørselen mot sine lokale ressurser og svarer med en liste over kandidatressurser. Klienten samler alle svarene og velger en eller flere kandidater for senere kall, slik som vist på Figur 14.
Figur 13: Interaksjonsdiagram for en katalogbasert oppdagelsestjeneste
Det er enkelt å få øye på at en katalogbasert oppdagelsestjeneste som beskrevet i (1) skaper minst nettverkstrafikk, mens den kringkastingsbaserte (2) gir de ferskeste og best oppdaterte opplysninger. Videre vil teknikk (2) forutsette at kringkastingsmeldinger er mulig å formidle, noe som normalt begrenser seg til ett subnett (noder på samme link). Eksempler på teknikk (2) er ARP og DHCP, mens (1) er brukt i DNS og ActiveDirectory.
Komplett og levende En oppdagelsestjeneste vil ideelt finne alle ressurser som passer til en forespørsel (komplett), og kun ressurser som for øyeblikket er tilgjengelig (levende). Alle har derimot opplevd at en Internet søkemotor henviser til web-sider som ikke svarer, eller er oppdatert til et annet innhold i mellomtiden.
En katalogbasert oppdagelsestjeneste vil kunne gi et komplett bilde av ressurser ved at de publiseres til katalogen når ressursen skapes. Derimot vil katalogen sjelden bli oppdatert når ressursen forsvinner (krasjer, tas ut av drift, stenges), slik at de henviser også til ressurser som ikke er levende, i det minste over en viss tidsperiode. En katalogbasert tjeneste vil derfor trenge mekanismer for å kunne vise til «levende» ressurser (eng. liveness property). To beslektede teknikker brukes for å fjerne «døde» ressurser, hjerteslag og leasing:
Hjerteslag – Katalogen sender regelmessige «hei» -meldinger til tjeneren som har ressursen, som returnerer en «klar» -melding for å vise at ressursen er tilgjengelig og levende. Dersom katalogen ikke mottar svar etter gjentagne «hei» -meldinger vil ressursen erklæres som død og fjernes fra katalogen.
Leasing – Nodene publiserer opplysninger om sine ressurser til katalogen med et utløpstidspunkt. Etter dette tidspunktet vil katalogen slette opplysningene dersom en ny leasing-melding ikke er mottatt. Med utløpstidpunktet kan noden «love» hvor lenge den vil klare å holde ressursen i live, dvs. den vil ikke gjøre noen forandringer i denne perioden.
Man kan se likheten mellom disse to mekanismene og problemstillingene knyttet til krasjdeteksjon i avsnitt 3.3. Leasing-meldingene lar nodene som eier ressursen selv avgjøre hvor ofte katalogen skal kontrollere om ressursen er levende, og kan på den måten redusere nettverkstrafikken som skapes. Hjerteslag-mekanismen er den enkleste å bruke, fordi den krever ikke at noden som eier ressursen tar stilling til utløpstid og den kan utføres «usynlig» for den øvrige programvaren.
Figur 14: Interaksjonsdiagram for en kringkastingsbasert oppdagelsestjeneste
En kringkastingsbasert oppdagelsestjeneste krever ingen separat katalogtjeneste som «megler» mellom ressursnoder og klientnoder. Den er spesielt attraktiv der ressurser (f.eks. en skriver, en DHCP-tjener, en mediatjener eller mediaspiller) og klienter naturlig befinner seg på samme subnett. Oppdagelsestjenesten vil aldri vise til «døde» ressurser, fordi den ber om svar fra ressursen hver gang den spør (sett bort fra muligheten for at ressursen dør øyeblikket senere), men vil generere mer nettverkstrafikk enn en katalogbasert mekanisme. Eksempler på slike oppdagelsestjenester finner vi i Simple Service Discovery Protocol (SSDP), og Apple Bonjour. SSDP er igjen basis for Microsofts lokalnett-tjenester og UPnP, Universal Plug-and-Play.
6.2 Tidstjenester
Som nevnt i avsnitt 3.4 finnes det ingen felles tidsangivelse for noder i et distribuert system. Det har likevel betydning for systemet at de har noenlunde samme tidsangivelse, og operasjonene i et distribuert system vil måtte utformes slik at de utføres riktig også ved små klokkeavvik.
En felles tidsangivelse kan oppnås gjennom å lytte til felles tidskilder. GPS-satellitter sender en svært nøyaktig tidsangivelse, og VHF radiosignaler med FM-RDS eller DAB inneholder også tidsinformasjon. DCF77 er betegnelsen på en radiosender utenfor Frankfurt a.m. som sender nøyaktig tidsinformasjon på 77.5 kHz. Radiostasjonen med kallesignalet WWV sender tidsinformasjon på HF-båndet på frekvensene 2.5, 5, 10, 15 og 20 MHz fra Colorado, USA. Radiosignaler vil ha en forutsigbar forsinkelse, og det er enkelt å oppnå nøyaktig tid med disse kildene.
Siden det er upraktisk og tidvis umulig å kople en radiomottaker og antenne til enhver node i systemet, er en tidsangivelse fra nettverket å foretrekke, selv om nettverket ikke har en forutsigbar forsinkelse. Derfor trengs en protokoll som kompenserer for variasjonen i forsinkelse så langt det er mulig.
Protokollen Network Time Protocol (NTP, beskrevet i RFC 5905) skal nå beskrives så enkelt som mulig. Klienten vil først estimere forsinkelsen til en tidstjener ved å sende en serie med meldinger som straks spretter tilbake. Gjennomsnittsverdien og variansen av den målte forsinkelsen vil danne grunnlaget for et estimat av forsinkelsen over denne ruten, ut fra den antagelsen at forsinkelsen er den samme i begge retninger. Når tidstjeneren siden annonserer riktig tid, adderer klienten den estimerte forsinkelsen til denne verdien.
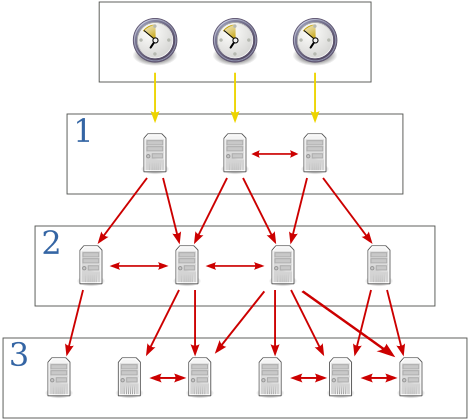
Figur 15: Hierarkiet av tidstjenere med «virkelige» klokkekilder øverst
NTP stiller ikke klokken direkte, fordi det vil bryte med kontinuiteten av tidsforløpet, særlig om klokken stilles bakover og samme tidspunkt derfor opptrer flere ganger. I stedet vil NTP endre klokkens takt til å tikke fortere eller langsommere slik at den gradvis tilpasser seg klokken fra tidstjeneren. Både estimeringen og justeringen skjer regelmessig, slik at avviket mellom klientens og tjenerens klokke stadig reduseres.
Figur 15 viser hvordan NTP lar tjenere skaper et hierarki med det øverste laget (kalt stratum-0) direkte koplet til en klokkekilde med forutsigbar forsinkelse, vist med gule piler. De øvrige røde pilene viser nettverksforbindelser med varierende forsinkelse. En slik hierarkisk organisering er nyttig av hensyn til skalerbarhet, og lar klientene hente tidsinformasjon fra flere kilder med mulighet for å øke nøyaktigheten.
NTP er implementert i alle de vanlige operativsystemene og er årsaken til at man sjelden trenger å stille datamaskinens klokke selv.
6.3 Replikeringstjenester
En viktig egenskap ved et distribuert systemer er at informasjon skal kunne lagres i flere kopier på ulike noder, slik at veien fra en klient til informasjonen blir kortere og raskere. Denne egenskapen bedrer både skalerbarheten og tilgjengeligheten ved systemet. Prosessen med å ajourholde slike lagernoder med innhold fra andre lagernoder kaller vi replikering, og ett slikt lager kalles et replikum (flertall replika). Metoden for ajourhold kan deles i to kategorier:
Passiv replikering betyr «etter behov» . Om et klient spør et replikum om et informasjonsobjekt som ikke finnes der, vil forespørselen videresendes til andre replika og hentes derfra. Samtidig lagres objektet i dette replikum for påfølgende spørringer. Dette minner meget om caching-mekanismen i HTTP-protokollen.
Aktiv replikering innebærer at objekter blir kopiert mellom replika uten at det blir spurt etter dem, i påvente av at de vil behøves på et senere tidspunkt. Objektene som skal replikeres blir utvalgt fra en spekulativ prosess, hvor man anslår en sannsynlighet for hvilke objekter som senere vil etterspørres på det enkelte replikum.
Hvordan skal nye objekter legges til et slikt system, og hvordan skal objekter blir endre? Her finnes det også to måter å organisere lageret på:
Likestilte replika betyr at det ikke er noen «master» . Objekter som legges til i ett replikum blir kopiert til andre replika, aktivt eller passivt. Objekter som blir oppdatert må kopieres til andre replika som har en tidligere versjon av dette objektet.
Figur 16: Et distribuert lager med likestile replika

Figur 16 viser denne prosessen, hvor oppdateringer på ett replikum kopieres til alle andre med en operasjon som kalles «atomisk multicast» , et begrep som i praksis ikke lar seg implementere. Utfordringen med et slikt arrangement er om det samme objektet oppdateres i flere replika samtidig, hvordan skal vi sørge for at alle ender opp med den samme versjonen av objektet? Dette fenomentet kalles oppdateringskonflikt og er et problem som ikke har noen generell og praktisk løsning.
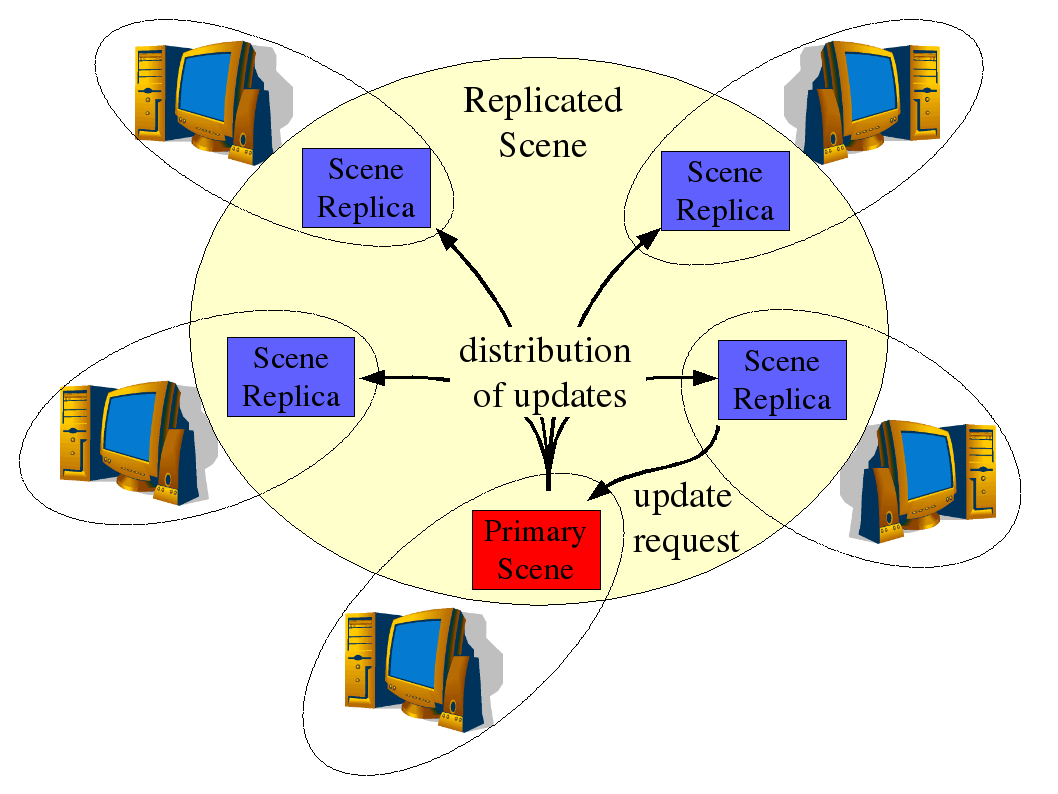
Figur 17: Et distribuert lager med primær- og sekundær-replika
Primær- og sekundær-replikum Alternativet til bruk av likestilte replika er å la ett replikum være primærkilden, alle tillegg og oppdateringer skal skje på denne. Primærreplikum har så ansvaret for å kopiere denne til de andre. Et slikt arrangement gjør at rekkefølgen på oppdateringene kan være lik i alle sekundær-replika, men har den svakhet at systemet ikke opprettholder tjenesten dersom primær-replikum krasjer.
Figur 17 viser dette arrangementet, der man ser hvordan rekkefølgen på operasjoner i replikeringsprosessen lar seg kontrollere bedre, slik at man kan unngå oppdateringskonflikter slik som i den forrige varianten.
Regler om rekkefølgen av oppdateringer Knyttet til replikering mellom likestilte replika finnes det noen teoretiske betraktninger over hvilken rekkefølge oppdateringer skal presenteres i. Vi er da ikke opptatt av forsinkelsen knyttet til replikering, men derimot hvordan hvert replikum presenterer objektene til sine klienter etter hvert som de blir oppdatert. Det finnes mange kategorier av rekkefølgeregler, her blir noen av dem presentert [10, avsnitt 7.2]:
Total (Perfekt) rekkefølge: Dersom objektet A oppdateres til A’ i ett replikum, og til A” i et annet replikum, skal alle replika presentere oppdateringen i enten rekkefølgen A-A’-A” eller A-A”-A’ til alle replika, dvs. alle skal se den samme sekvensen av oppdateringer.
Kausal rekkefølge: Dersom objektet A blir oppdatert til A’ i ett replikum, og et annet replikum oppdaterer A’ til A”, skal alle replika se sekvensen A-A’-A”, fordi A er årsaken til A’ som igjen er årsaken til A”. Dvs. at årsaken til en oppdatering skal alltid vises før effekten av oppdateringen.
FIFO rekkefølge: Dersom ett replikum oppdaterer objektet A til A’ og siden til A”, mens en annen node oppdater A til A”’, skal andre replika se enten rekkefølgen A-A’-A”-A”’, eller A-A’-A”’-A”, eller A-A”’-A’-A”. Dvs. at oppdateringer som er skjedd i ett replikum skal vises i denne rekkefølgen hos alle. Oppdateringer gjort i ulike replika kan derimot presenteres ulikt.
Ubestemt rekkefølge: Ingen rekkefølge er påkrevet, men derimot kreves det at alle replika ender opp med den samme versjonen «over tid» . I eksemplet over kan det betyr at enten A” eller A”’ sees likt i alle replika, mens rekkefølgen underveis er ubestemt.
Disse rekkefølgekravene er listet opp fra «streng» til «fri» . Total rekkefølge er komplisert å oppnå og vil i praksis ikke være mulig å garantere i et nettverk uten garanterte leveringstider. Ubestemt rekkefølge vil være lett å tilby, men vil ikke tilfredsstille kravene som stilles av mange anvendelser. Kausal og FIFO rekkefølge er derimot nyttige modeller som er mulig å tilby i praksis.
Oppdatering i tradisjonelle filtjenere Legg merke til at tradisjonelle filtjenere, slik de vanligvis finnes i tradisjonelle lokalnett, ikke har noen rekkefølgemekanismer overhodet, og har ingen beskyttelse mot oppdateringskonflikter. Mekanismen for å låse dokumenter i f.eks. Microsoft Office er basert på at applikasjonen skriver en «lås» på filen og forutsetter at andre tar hensyn til denne. Denne mekanismen fungerer derfor ikke i et replikert filsystem slik man finner det i f.eks. Dropbox.
6.4 Lokasjonstjenester
Et vanlig forhold i mobile systemer er at brukeren får sin betjening basert på sin lokasjon, f.eks. «finn nærmeste bensinstasjon» . Mobile systemer er alltid distribuerte, så spørsmålet om hvordan klientens lokasjon kan bestemmes er et tema innenfor det samme fagfeltet.
Hvilke kjennetegn ved en klient kan indikere en lokasjon?
IP-adressen er regionbasert, dvs. at stadig smalere subnettadresser bestemmer en stadig snevrere geografisk posisjon. Selv om klienten benytter dynamiske IP-adresser basert på DHCP-protokoll vil adressene ligge innenfor et subnett som indikerer en lokasjon med tilstrekkelig nøyaktighet for mange typer anvendelser (f.eks. en værmelding). Der hvor klienten henvender seg til en tjeneste med en annen IP-adresse enn sin egen, f.eks. der hvor trafikken går gjennom en NAT-enhet (Network Address Translation) eller via et VPN (Virtual Private Network) vil ikke lokasjonen kunne påvises med IP-adresse.
GPS-posisjon er som kjent svært nøyaktig og vil tilfredsstille alle praktiske formål der klientutstyret har en GPS-mottaker og befinner seg innen GPS-satellittenes rekkevidde.
WiFi- og Bluetooth-signaler kan bidra til å bestemme lokasjon, dersom navnet på et WiFi-nettverk (SSID) er knyttet til et sted. Dersom WiFi-radioen på klientenheten er slått på vil SSID-verdier være tilgjengelig for lokasjonsbestemmelse. Nøyaktigheten til den estimerte lokasjonen avhenger av WiFi-aksesspunktets rekkevidde, men kan bedres med triangulering mellom flere WiFi-aksesspunkter. Bluetooth-enheter kan brukes på samme måten, men det eksisterer ikke noen database over Bluetooth-navn og deres posisjon, slik at anvendelsen blir begrenset i utbredelse til f.eks. rom i en bygning [9].
Basestasjoner for mobiltelefoni I et cellulært mobilnett vil en klient typisk være tilknyttet sin nærmeste basestasjon, noe som gir en lokasjonsbestemmelse med noen få kilometers nøyaktighet. Denne mekanismen forutsetter naturligvis at klientenheten er tilkoblet mobilnettet. Det er ikke klienten selv som rapporterer sin posisjon til det distribuerte systemet, men mobiloperatøren.
Man ser mange av disse mekanismene i daglig bruk på Internet gjennom f.eks. Google Geolocation API. I Google Maps finner man sin egen lokasjon bestemt av GPS med stor nøyaktighet, med dårligere nøyaktighet der mobilnettet gir lokasjonsdata, og på «tidslinjen» kan man finne hvilke butikker man har besøkt, da bestemt av WiFi-SSID.
Privat lokasjon Lokasjonsopplysninger er i noen grad private og sensitive, og det bør være mulig for en klient å skjule sin lokasjon fra det distribuerte systemet. En klient kan velge å holde tilbake opplysninger om GPS-signaler, WiFi-SSID og Bluetooth-navn, men ikke opplysninger om IP-adresse eller basestasjon for mobiltelefoni. Lokasjonsbestemmelse basert på IP-adresse kan i noen grad skjules gjennom bruk av VPN. Opplysninger om basestasjon kan ikke skjules, men klienten kan velge andre radiobærere for å unndra seg lokasjonsbestemmelse.
Autentisert lokasjon Der hvor det knytter seg rettigheter og privilegier til en lokasjon (f.eks. at man får bruke anvendersystemet kun innenfor gjerdet til en militærleir) er det nødvendig å kunne forsyne systemet med autentiske lokasjonsopplysninger, som ikke skal kunne forfalskes. Med autentisert lokasjonsinformasjon følger det derimot noen problemstillinger:
- Rettigheter/privilegier gis normalt til en person, ikke til en utstyrsenhet
- Den målte lokasjonen hører til utstyrsenheten, ikke til personen
- Uønsket programvare (skadevare) vil kunne modifisere lokasjonsinformasjon før den sendes
- Koplingen mellom en GPS-mottaker og klientmaskinen kan angripes slik at lokasjonsdataene endres
- Det er mulig å generere falske WiFi-SSID, falske Bluetooth-navn og endog falske GPS-signaler.
For å hindre forfalsket informasjon må man ikke bare beskytte systemet mot utvendige angripere, men også angrep fra enhetens bruker, som har uinnskrenket tilgang til maskinvaren i tillegg til den ordinære brukerbetjeningen.
Autentisert lokasjonsinformasjon forutsetter derfor at (1) forbindelsen mellom radiomottakeren (GPS, WiFi, Bluetooth) er forseglet slik at den ikke kan påvirkes uten at radioen blir ødelagt, (2) at klientenhetens programvare er forseglet på en slik måte at den slutter å virke dersom den blir modifisert, (3) radiosignalene som mottas skal være på en form som ikke lett lar seg forfalske.
Ingen av disse tre forutsetningene er enkle å innfri, og krever både spesialtilpasset programvare og maskinvare.
6.5 Gjenopprettingstjenester
Knyttet til uunngåelige systemkrasj er spørsmålet om gjenoppretting av en riktig systemtilstand etter ny oppstart. Ved en krasj vil det kunne være operasjoner som er under utføring, og det er ikke mulig å si om disse operasjonene rakk å fullføres, om de ble påbegynt, eller om de stoppet midtveis med halvgjort effekt og dataene i feil tilstand. Eksempler på det siste er om et flysete er merket som «reservert» , men uten at det er knyttet en passasjer til det. Etter oppstart risikerer man at flysetet aldri blir brukt (se avsnitt 3.3 om uavhengig krasj og feil). Slike feil kan oppstå når en sammensatt operasjon blir avbrutt midtveis.
For å styre og beskytte sammensatte operasjoner på et felles lager er det vanlig å utføre operasjonene samlet på en måte som kalles atomiske og varige. En atomisk operasjon vil være udelt, dvs. enten ikke påbegynt eller fullført. Ingen mellomresultater er synlige for andre som bruker de samme dataene. En operasjon er varig når resultatet er permanent lagret i maskinen, dvs. vil bestå en krasj og en omstart.
Tjenesten som besørger atomiske og varige operasjoner kalles en transaksjonsbeholder (eng. transaction container eller -monitor). Den samler opp delene i en sammensatt operasjon og utfører dem samlet slik at egenskapene nevnt ovenfor beholdes, og synkroniserer med operasjoner fra andre klienter slik at konflikter unngås.
Transaksjonsmonitoren skal også ha oppgaven med å gjenopprette tilstanden ved systemkrasj. Det er i prinsippet ikke mulig å sørge for at et system er i kjent og riktig tilstand til enhver tid, slik at en ny oppstart kan skje uten en oppryddingsfase. Systemet må derimot ta «snapshots» av systemtilstanden og sørge for at alle operasjoner legger igjen «logg» som gjør at en oppryddingsfase kan fastslå hvilke operasjoner som er påbegynt og enten fullføre disse operasjonene eller nullstille dem.
En transaksjonsbeholder samarbeider tett med operativsystemet og lagringssystemet på maskinen for å skape de nødvendige vilkårene for å lage snapshots og loggføring med atomiske og varige operasjoner.
Idempotente operasjoner En enklere strategi for gjenoppretting er å sørge for at samme operasjon kan utføres mer enn én gang uten at systemets tilstand forstyrres. Operasjonen «slett filen xyz» er idempotent, det er også operasjonen «skriv verdien 234 i posisjon 456 i fil xyz» . Derimot er ikke «addér verdien 45 til variabel a» idempotent, heller ikke «skriv en tekst bakerst i loggfilen».
I den grad et system kan bygges opp av idempotente operasjoner er dette en mye enklere måte å gjenopprette riktig systemtilstand på: Alle påbegynte operasjoner som ikke har kvittert for sin fullføring kjøres på nytt etter oppstart. En liste over disse operasjonene må legges på et permanent lager slik at de overlever en systemkrasj. Dessverre er det sjelden mulig å designe et distribuert system kun med idempotente operasjoner. Fortsatt må operasjonene synkroniseres slik at de er atomiske og isolert fra andre klienter.
Gjenoppretting etter krasj er et komplisert problem som beror på at enkelte fysiske prosesser i maskinen er atomiske i sin natur, f.eks. skriving av en sektor på en diskoverflate.
6.6 Tjenester for tillitshåndtering
I mange tilfeller vil tjenester kun tilbys til klientprosesser med de riktige rettigheter eller privilegier, som er et uttrykk for den tilliten systemet har til denne klienten. Slik tillit skal forvaltes, dvs. opprettes, fjernes og endres, og den skal publiseres på en måte som (1) ikke kan forfalskes og (2) kan valideres (kontrolleres) av tjenestetilbyderen.
Symmetrisk På tilsvarende måte skal systemet ha tillit til en tjener, dvs. at tjeneren har rett til å tilby de aktuelle tjenestene. Forvaltning, publisering og validering av tillit bør foregå begge veier i et klient-tjener forhold og være symmetrisk. I et distribuert system er ikke en tjener mer troverdig enn en klient, og begge skal derfor presentere sine privilegier på lik linje.
Kontrollen av privilegier er en todelt prosess. Først skal klienten autentiseres for å bindes til en identifikator, deretter skal man bestemme hvilke privilegier som er knyttet til denne identifikatoren. Med «klienten» mener vi sjelden selve maskinen, men bestemte prosesser i maskinen, som typisk er under kontroll («eies av» ) en bruker. Da er det en person som innehar tillit, og som delegerer denne tilliten til en prosess i en datamaskin som brukeren starter og kontrollerer.
Autentisering foregår ved at brukeren/prosessen beviser noe den vet, eller noe den har. For at ikke denne hemmeligheten skal misbrukes av andre, vil det fremvises et «proof of possession» i form av en digital signatur, en hash-verdi av et passord eller lignende. Proof of possession må være utformet slik at den kan valideres av mottakeren, bindes til en identifikator som igjen bindes til den påfølgende transaksjonen.
En mye brukt standard for autentisering er EAP, som lar en bruker supplere et passord (eller et sertifikat), som igjen kan kontrollere dette mot en såkalt Radius-tjener.
Det er i praksis sjelden at en tjener blir autentisert overfor klienten. Det nærmeste vi kommer er HTTPS (basert på TLS-protokollen) som sikrer at tilkoblingen fra en web-leser går til en web-tjener som «eier» DNS-navnet i URL’en, men dette er en relativt svak form for autentisering.
Adgangskontroll er et litt gammeldags ord for å kontrollere privilegiene til brukeren/prosessen. Det er gammeldags fordi vi bruker denne metoden til mye mer enn bare å gi «adgang» til en tjeneste eller en fil, f.eks. gi tillatelse til å skrive en etterretningsrapport eller ildledningsordre. Ofte skjer adgangskontroll som en separat prosess etter at autentiseringen er fullført, basert på andre protokoller og et separat datalager.
Adgangskontroll vil i praksis være knyttet til en spesifikk leverandør, dvs. at programvaren på klient og tjener er laget av samme produsent. Det finnes åpne standarder, f.eks. den kalt XACML, men den er lite i bruk i hyllevareprodukter.
Autentisering og adgangskontroll kan resultere i at klienten mottar akkreditiver, som er dataelementer som den siden fremviser til en tjener i forbindelse med tjenestekall, tjeneren vil i den forbindelse validere akkreditivene. Bruk av akkreditiver har den fordel av de kan brukes mellom to parter uten å involvere tjenester for autentisering eller adgangskontroll. I et distribuert system betyr denne egenskapen at man blir mindre avhengig av forbindelser gjennom nettverket.
Nøkkelsertifikater spiller en vesentlig rolle i distribuert tillitshåndtering. Sertifikatet er et dataelement som inneholder en offentlig nøkkel, en identifikator, en gyldighetsperiode og litt til, alt sammen forseglet med en digital signatur fra en sertifikatutsteder (eng. Certificate Authority, CA) som alle parter i systemet har tillit til. Sammen med sine private nøkler kan nå partene autentisere seg overfor hverandre uten hjelp fra en sentral tjener til å validere noen akkreditiver. Dersom opplysningene i sertifikatet også kan indikere privilegiene til eieren (altså den brukeren som identifikatoren peker på) kan adgangskontroller foregå på samme vis. Nøkkelsertifikatet vil her brukes som akkreditiv.
7. Oppsummering
Dette tekstkapittelet har hatt som mål å presentere et utvalg av teoretiske og teknologiske emner innen fagfeltet distribuerte systemer. De emnene som er omtalt er nyttige for dem som skal arbeide med anskaffelser, vedlikehold, drift og konfigurasjon av distribuerte systemer.
Teksten har i liten grad kommet inn på problemstillinger innen programmeringsfaget. Konstruksjonen av distribuerte systemer krever andre programmeringsbiblioteker og andre programmeringsteknikker enn sentraliserte anvendelser, og en person med ønske om å programmere distribuerte systemer bør gå dypere ned i studier av de relevante delemnene, og fremfor alt tilegne seg ferdigheter i et programmeringslaboratorium.
I dag er de fleste informasjonssystemer distribuerte, og kjennskap til fagfeltet ned til det nivået som er beskrevet i dette kapitlet er helt nødvendig for å kunne forvalte et system på en forsvarlig måte.
8. Litteraturliste
[1] A. Carzaniga, D.S. Rosenblum, and A.L. Wolf (2001) Design and Evaluation of a Wide-Area Event Notification Service ACM Transactions on Computer Systems, 19(3):332-383, August 2001.
[2] Fongen, A. (2002) Operativsystemer – et Java-perspektiv, NKI-forlaget 2002, ISBN 82-562-5743-1
[3] Kurose, J. and Ross, K. (2017) Computer Networking, a Top-Down Approach 7th ed. Pearson 2017.
[4] Stoica, I., Morris, R., Karger, D., Kaashoek, M. F. and Balakrishnan, H. (2001) Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications In: SIGCOMM 2001, 27.-31.August 2002, San Diego, California, pp. 149-160
[5] Rajiv Ranjan, Aaron Harwood and Rajkumar Buyya (2008) Peer-to-Peer Based Resource Discovery in Global Grids: A Tutorial. IEEE Communications Surveys & Tutorials Volume: 10 , Issue: 2
[6] Anders Fongen, Federico Mancini (2013) The Integration of Trusted Platform Modules into a Tactical Identity Management System IEEE MILCOM, San Diego, USA, 2013
[7] Brian Shand, Peter Pietzuch, Ioannis Papagiannis, Ken Moody, Matteo Migliavacca, David M. Eyers, Jean Bacon (2011) Security Policy and Information Sharing in Distributed Event-Based Systems In: Studies in Computational Intelligence,Volume 347, Springer, Pages 151-172
[8] Wikipedia OASIS SOA Reference Model. Online: https://en.wikipedia.org/wiki/OASIS_SOA_Reference_Model [visited 7 dec 2018]
[9] Fongen A., Larsen, C., Taylor, S.J.E (2007) Location Based Mobile Computing – A tuplespace perspective, Mobile Information Systems, (2)2,3 pp. 135-149.
[10] Tanenbaum A., Steen M. van (2002): Distributed Systems: Principles and Paradigms Prentice Hall